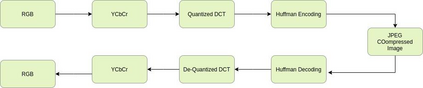
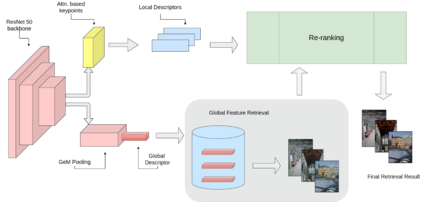
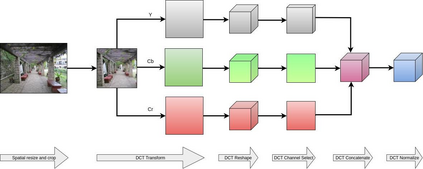
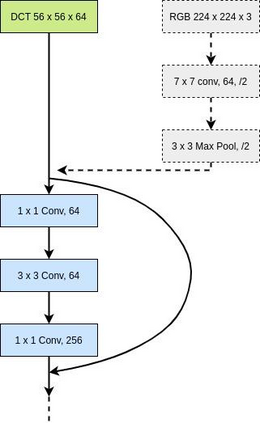
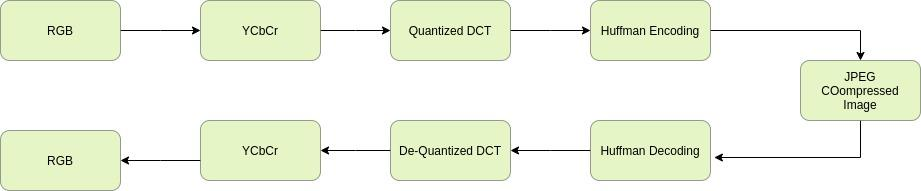
Content-based image retrieval (CBIR) systems on pixel domain use low-level features, such as colour, texture and shape, to retrieve images. In this context, two types of image representations i.e. local and global image features have been studied in the literature. Extracting these features from pixel images and comparing them with images from the database is very time-consuming. Therefore, in recent years, there has been some effort to accomplish image analysis directly in the compressed domain with lesser computations. Furthermore, most of the images in our daily transactions are stored in the JPEG compressed format. Therefore, it would be ideal if we could retrieve features directly from the partially decoded or compressed data and use them for retrieval. Here, we propose a unified model for image retrieval which takes DCT coefficients as input and efficiently extracts global and local features directly in the JPEG compressed domain for accurate image retrieval. The experimental findings indicate that our proposed model performed similarly to the current DELG model which takes RGB features as an input with reference to mean average precision while having a faster training and retrieval speed.
翻译:在像素域上基于内容的图像检索系统(CBIR)在像素域上使用低层次的特征,如颜色、质地和形状等,来检索图像。在这方面,文献中研究了两种类型的图像显示方式,即局部和全球图像特征。从像素图像中提取这些特征并将其与数据库中的图像进行比较是非常费时的。因此,近年来在压缩域直接完成图像分析方面做出了一些努力,但计算较少。此外,我们日常交易中的大多数图像都存储在JPEG压缩格式中。因此,我们最好能够直接从部分解码或压缩的数据中提取这些特征,并将其用于检索。我们在此提议一个统一的图像检索模式,将DCT系数作为输入,并直接在JPEG压缩域直接提取全球和地方特征,以便准确检索图像。实验结果表明,我们拟议的模型与当前的DELG模型类似,该模型采用RGB特征作为参考平均精确度,同时具有更快的培训和检索速度。