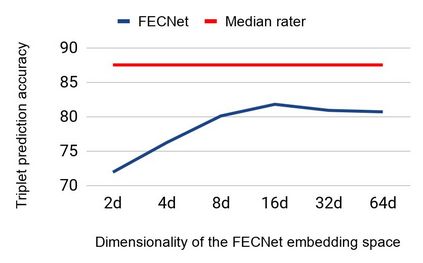
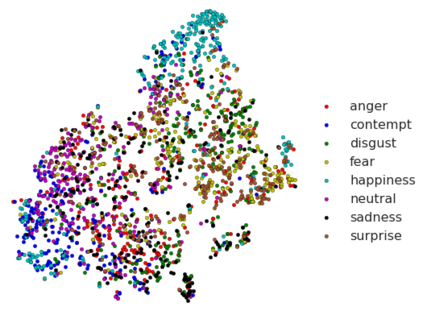
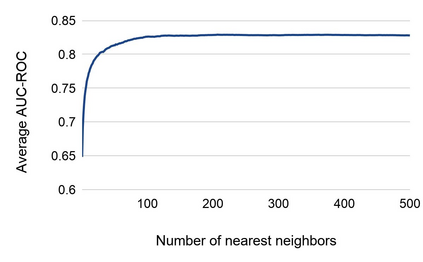
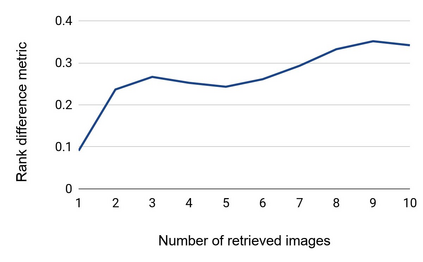
Most of the existing work on automatic facial expression analysis focuses on discrete emotion recognition, or facial action unit detection. However, facial expressions do not always fall neatly into pre-defined semantic categories. Also, the similarity between expressions measured in the action unit space need not correspond to how humans perceive expression similarity. Different from previous work, our goal is to describe facial expressions in a continuous fashion using a compact embedding space that mimics human visual preferences. To achieve this goal, we collect a large-scale faces-in-the-wild dataset with human annotations in the form: Expressions A and B are visually more similar when compared to expression C, and use this dataset to train a neural network that produces a compact (16-dimensional) expression embedding. We experimentally demonstrate that the learned embedding can be successfully used for various applications such as expression retrieval, photo album summarization, and emotion recognition. We also show that the embedding learned using the proposed dataset performs better than several other embeddings learned using existing emotion or action unit datasets.
翻译:自动面部表达式分析的现有大部分工作侧重于感知分解或面部动作单位检测。 但是, 面部表达式并不总是完全划入预先定义的语义分类。 另外, 在动作单位空间中测量的表达式之间的相似性不一定与人类如何看待表达式相似。 不同于先前的工作, 我们的目标是使用一个模拟人类视觉偏好的紧凑嵌入空间, 持续描述面部表达式。 为了实现这一目标, 我们收集了一个大型面部和侧面部数据组, 其形式为: 表达式 A 和 B 与表达式 C 相比在视觉上更加相似, 并使用此数据组来训练一个产生紧凑( 16 维) 表达式嵌入的神经网络。 我们实验性地证明, 学到的嵌入式可以成功地用于表达式检索、 相片专辑和情感识别等各种应用。 我们还表明, 使用所拟议的数据集所学的嵌入式比利用现有情感或动作单位数据集所学的其他几个嵌入式要好得多。