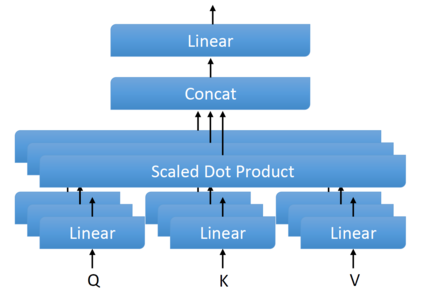
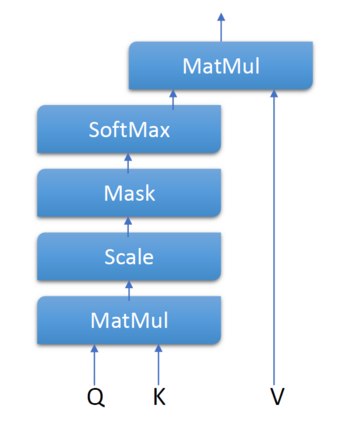
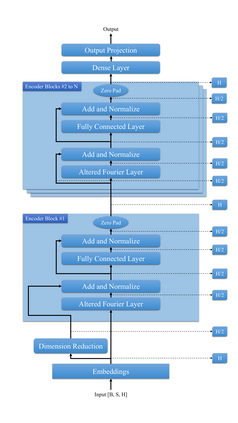
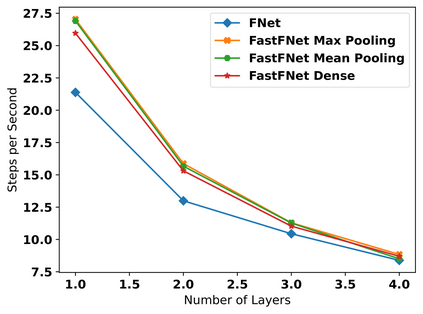
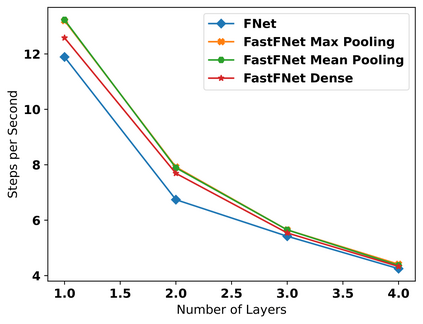
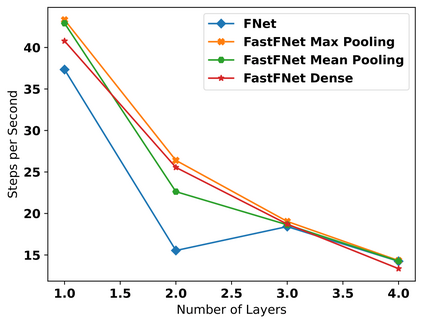
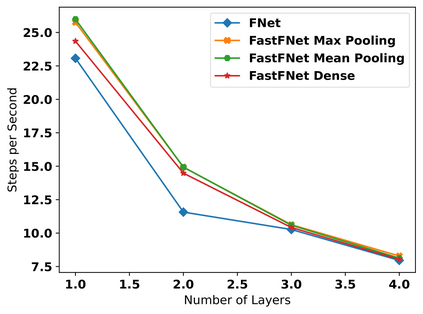
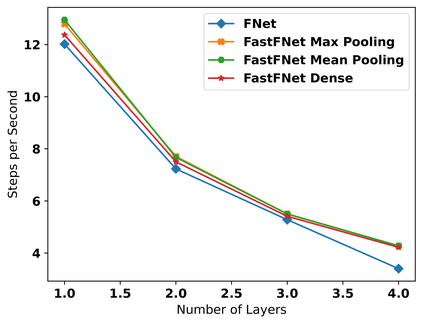
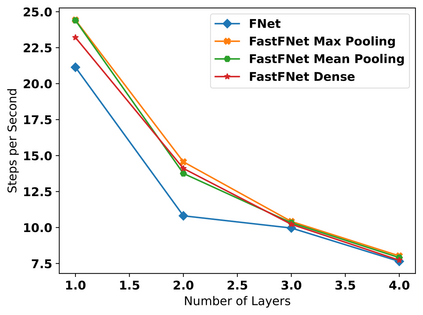
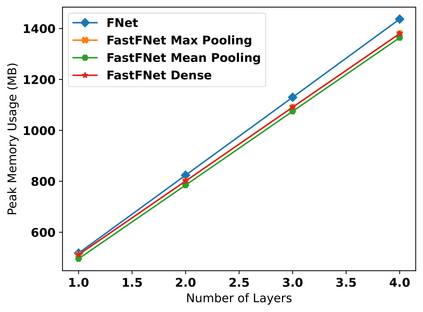
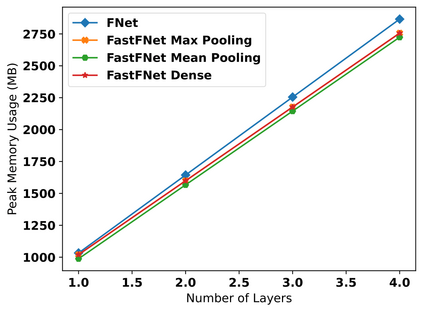
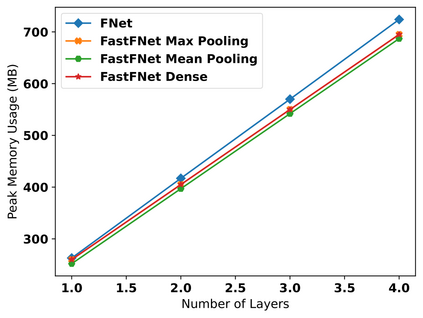
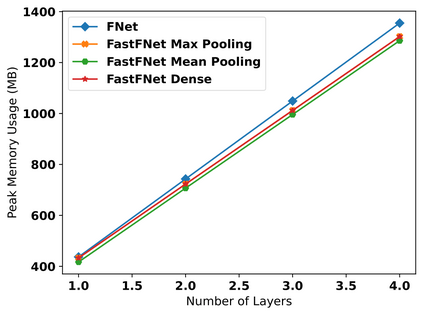
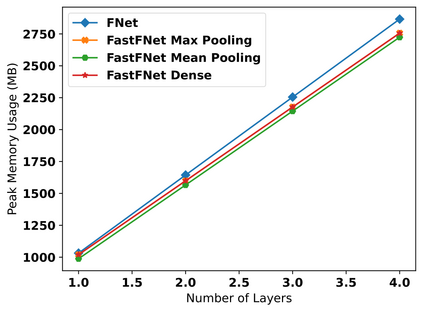
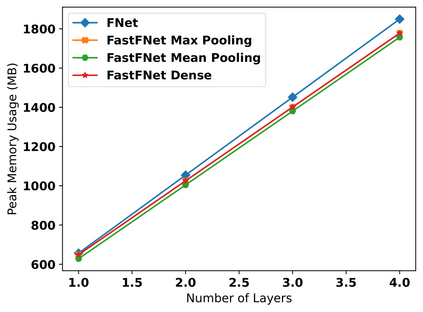
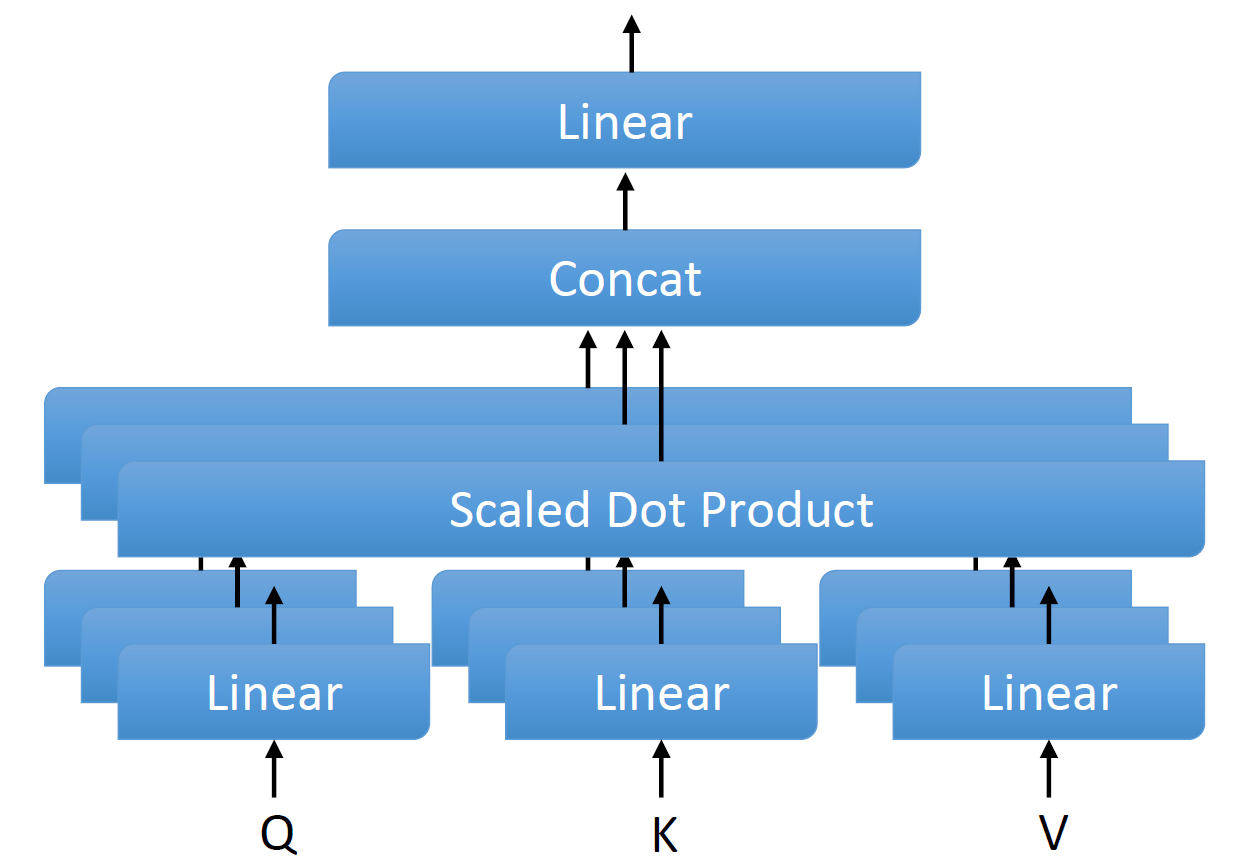
Transformer-based language models utilize the attention mechanism for substantial performance improvements in almost all natural language processing (NLP) tasks. Similar attention structures are also extensively studied in several other areas. Although the attention mechanism enhances the model performances significantly, its quadratic complexity prevents efficient processing of long sequences. Recent works focused on eliminating the disadvantages of computational inefficiency and showed that transformer-based models can still reach competitive results without the attention layer. A pioneering study proposed the FNet, which replaces the attention layer with the Fourier Transform (FT) in the transformer encoder architecture. FNet achieves competitive performances concerning the original transformer encoder model while accelerating training process by removing the computational burden of the attention mechanism. However, the FNet model ignores essential properties of the FT from the classical signal processing that can be leveraged to increase model efficiency further. We propose different methods to deploy FT efficiently in transformer encoder models. Our proposed architectures have smaller number of model parameters, shorter training times, less memory usage, and some additional performance improvements. We demonstrate these improvements through extensive experiments on common benchmarks.
翻译:以变压器为基础的语言模型利用关注机制,在几乎所有自然语言处理(NLP)任务中大幅度改进业绩。类似的关注结构也在其他几个领域进行了广泛研究。虽然关注机制极大地提高了模型的绩效,但其四重复杂性妨碍了对长序列的高效处理。最近的工作重点是消除计算效率低下的不利之处,并表明变压器模型仍然可以在没有关注层的情况下取得竞争性结果。一项开创性研究提议FNet,它将关注层改为变压器编码器结构中的Fourier变压器(FT),FNet在原有变压器编码器模型方面实现了竞争性的绩效,同时通过消除注意机制的计算负担加快了培训进程。然而,FNet模型忽略了传统信号处理中FT的基本特性,而这种特性可用来进一步提高模型的效率。我们提出了在变压器编码器模型中高效地部署FTT的方法。我们提出的结构有较少的模型参数、较短的培训时间、记忆用少和一些额外的绩效改进。我们通过对共同基准进行广泛的试验来展示这些改进。