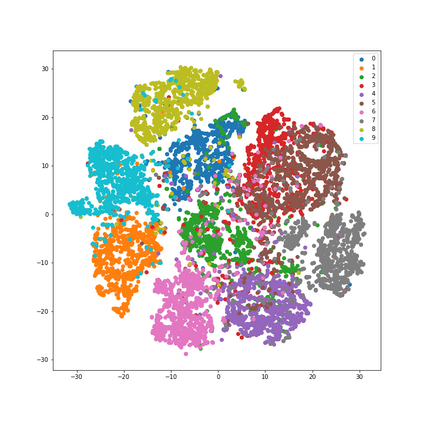
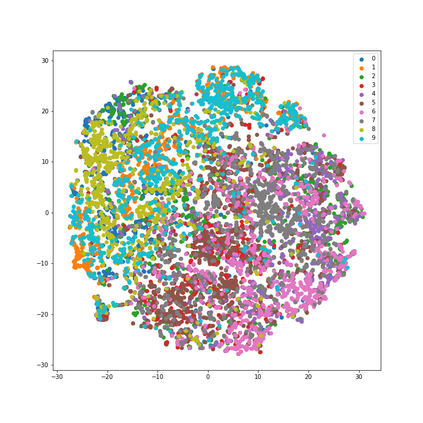
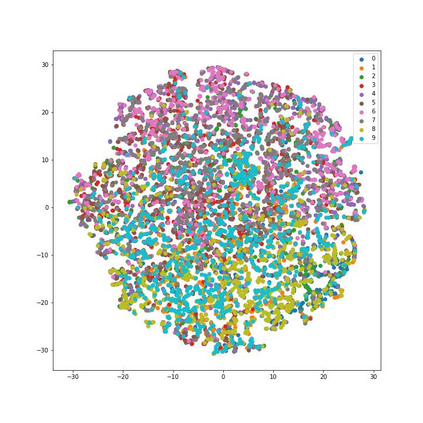
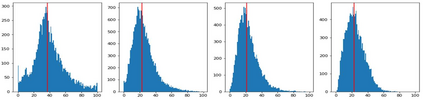
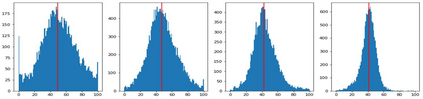
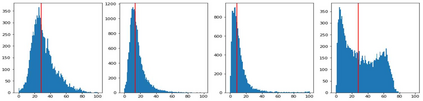
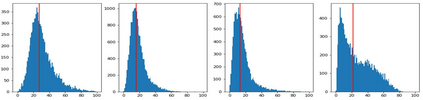
How can neural networks trained by contrastive learning extract features from the unlabeled data? Why does contrastive learning usually need much stronger data augmentations than supervised learning to ensure good representations? These questions involve both the optimization and statistical aspects of deep learning, but can hardly be answered by analyzing supervised learning, where the target functions are the highest pursuit. Indeed, in self-supervised learning, it is inevitable to relate to the optimization/generalization of neural networks to how they can encode the latent structures in the data, which we refer to as the feature learning process. In this work, we formally study how contrastive learning learns the feature representations for neural networks by analyzing its feature learning process. We consider the case where our data are comprised of two types of features: the more semantically aligned sparse features which we want to learn from, and the other dense features we want to avoid. Theoretically, we prove that contrastive learning using $\mathbf{ReLU}$ networks provably learns the desired sparse features if proper augmentations are adopted. We present an underlying principle called $\textbf{feature decoupling}$ to explain the effects of augmentations, where we theoretically characterize how augmentations can reduce the correlations of dense features between positive samples while keeping the correlations of sparse features intact, thereby forcing the neural networks to learn from the self-supervision of sparse features. Empirically, we verified that the feature decoupling principle matches the underlying mechanism of contrastive learning in practice.
翻译:神经网络如何通过对比性学习提取数据? 对比性学习通常需要比监督性学习更强的数据增强,以确保良好的表现? 为什么对比性学习通常需要比监督性学习更强的数据增强,以确保良好的表现? 这些问题既涉及深层次学习的优化和统计方面,但很难通过分析监督性学习来回答,因为目标功能是最大的追求。 事实上,在自我监督的学习中,与神经网络优化/普及相联系是不可避免的,它们如何将数据中的潜伏结构编码起来,我们称之为特征学习过程。在这项工作中,我们正式研究对比性学习如何通过分析其特征学习过程来了解神经网络的特征表现。我们考虑的是,我们的数据包括两种特征:我们想从中学习的更精致一致的稀疏特性,以及我们想避免的其他密度特征。理论上,我们证明,对比性学习使用 $mathbf{ReU} 来理解想要的稀疏特性,如果采用适当的增强性过程,那么我们就可以理解。 我们提出一个基本原则叫做 exprevision{flial decregial recolal recul recul recul reculity reculational resmactactactivactal resmactmactal ration ral rence,我们如何学习如何将如何如何使机能在不断校正校正正校正校正 。