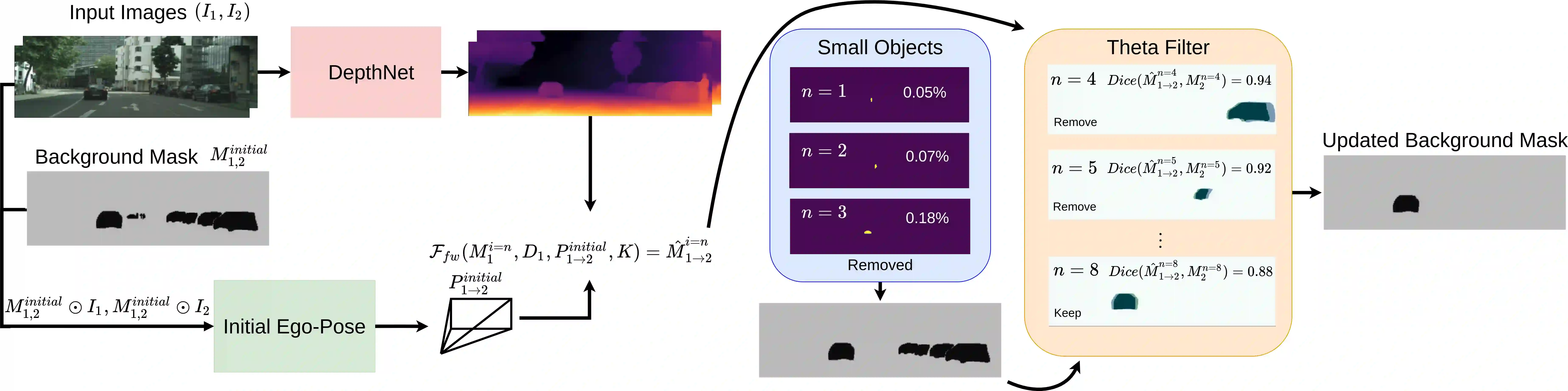
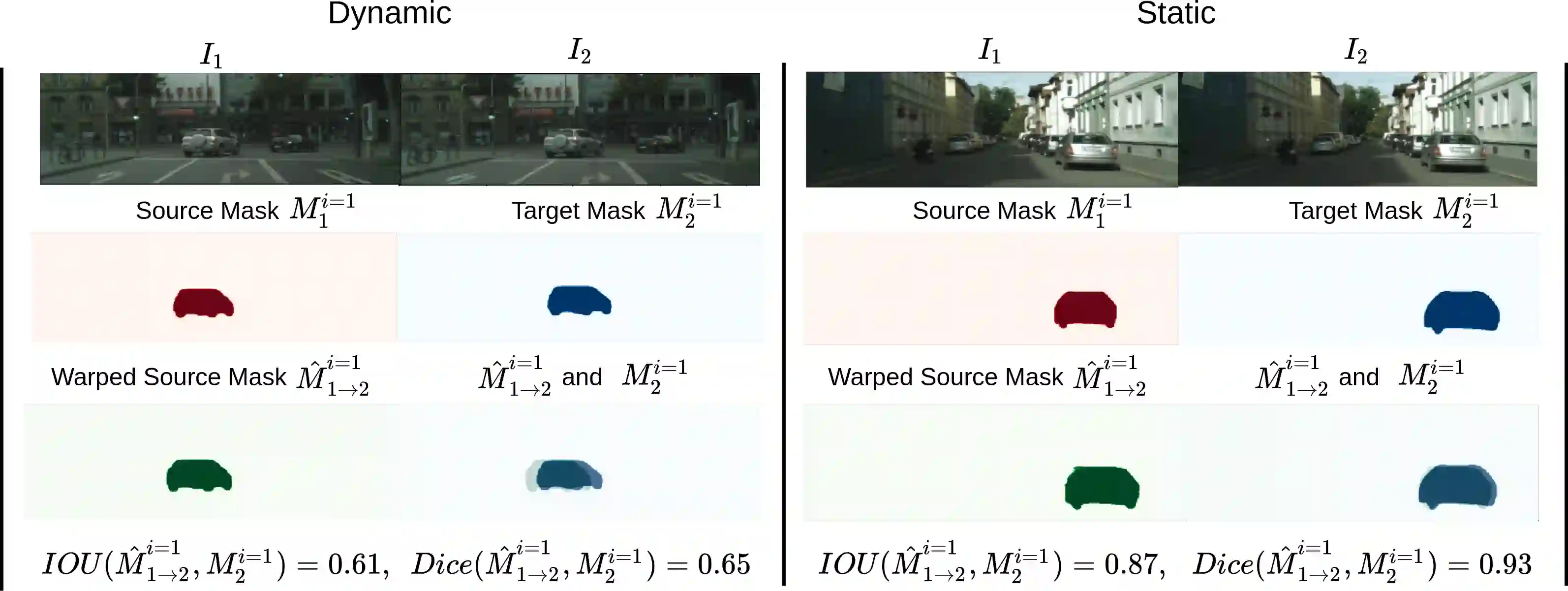
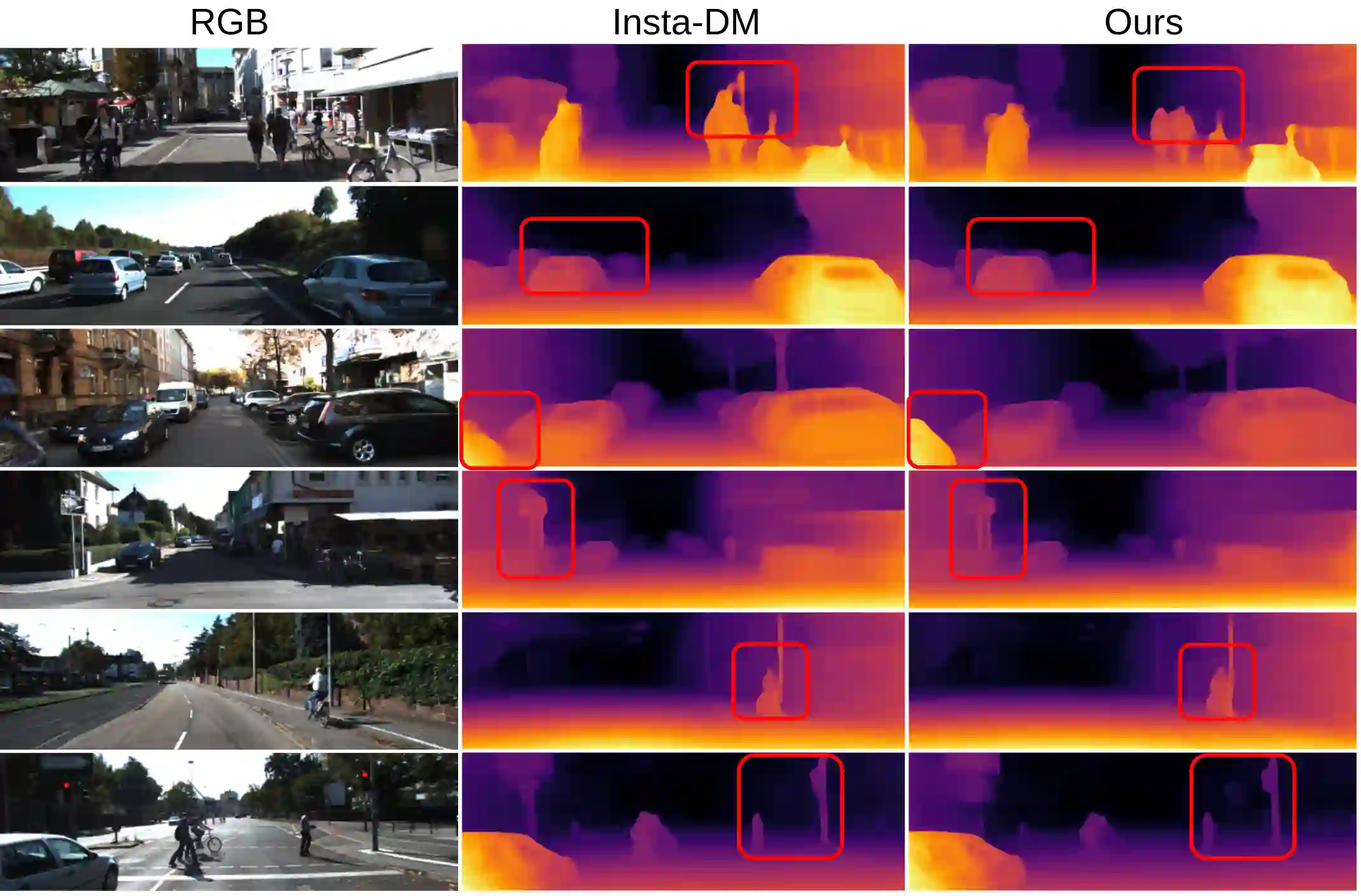
Self-supervised monocular depth estimation has been a subject of intense study in recent years, because of its applications in robotics and autonomous driving. Much of the recent work focuses on improving depth estimation by increasing architecture complexity. This paper shows that state-of-the-art performance can also be achieved by improving the learning process rather than increasing model complexity. More specifically, we propose (i) only using invariant pose loss for the first few epochs during training, (ii) disregarding small potentially dynamic objects when training, and (iii) employing an appearance-based approach to separately estimate object pose for truly dynamic objects. We demonstrate that these simplifications reduce GPU memory usage by 29% and result in qualitatively and quantitatively improved depth maps. The code is available at https://github.com/kieran514/Dyna-DM.
翻译:近些年来,自我监督的单眼深度估计一直是一项密集研究的主题,因为它应用于机器人和自主驾驶。最近许多工作的重点是通过增加结构的复杂性来改进深度估计。本文表明,通过改进学习过程,而不是增加模型的复杂性,也可以实现最先进的性能。更具体地说,我们提议:(一) 在培训过程中,仅使用无变动性对最初几个时代造成损失,(二) 在培训时忽视小型潜在动态物体,(三) 采用外观方法,分别估计物体对真正动态物体的影响。我们证明,这些简化将GPU的内存用量减少29%,并产生质量和数量上改进的深度图。该代码可在https://github.com/kiran514-DMD中查阅。