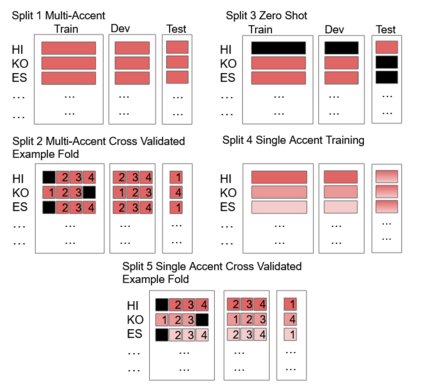
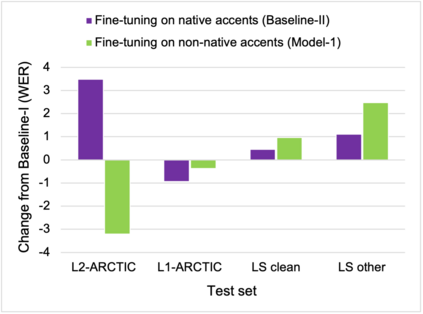
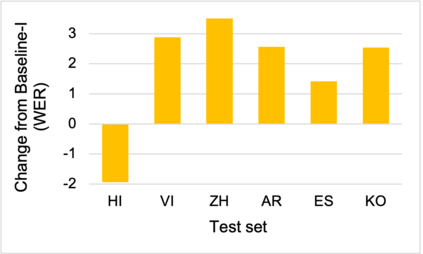
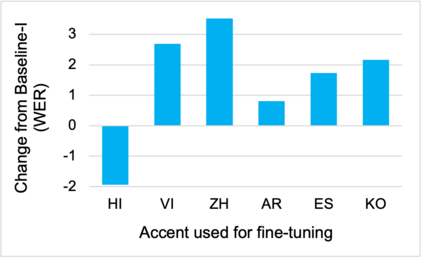
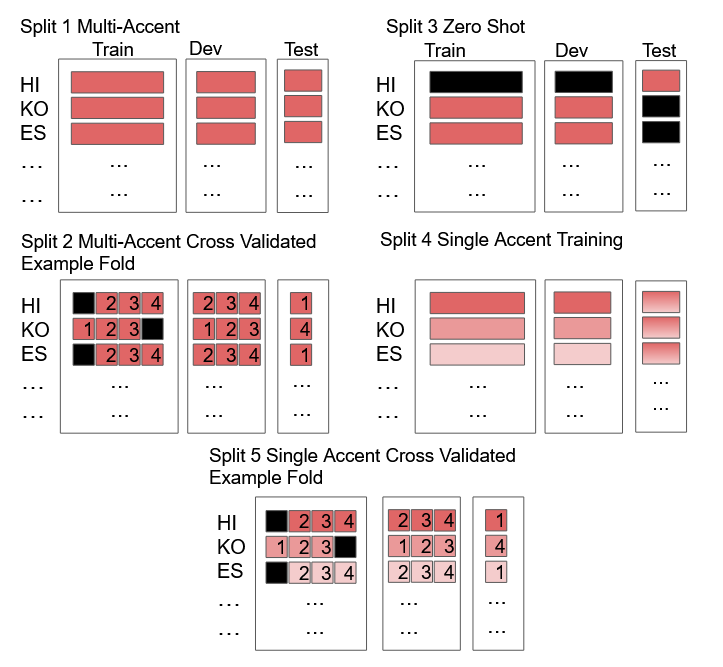
To address the performance gap of English ASR models on L2 English speakers, we evaluate fine-tuning of pretrained wav2vec 2.0 models (Baevski et al., 2020; Xu et al., 2021) on L2-ARCTIC, a non-native English speech corpus (Zhao et al., 2018) under different training settings. We compare \textbf{(a)} models trained with a combination of diverse accents to ones trained with only specific accents and \textbf{(b)} results from different single-accent models. Our experiments demonstrate the promise of developing ASR models for non-native English speakers, even with small amounts of L2 training data and even without a language model. Our models also excel in the zero-shot setting where we train on multiple L2 datasets and test on a blind L2 test set.
翻译:为了解决英语ASR模型在L2讲L2英语者方面的性能差距,我们评估了预先培训的wav2vec 2.0模型(Baevski等人,2020年;Xu等人,2021年)的微调(Baevski等人,2020年);关于L2-ARCTIC的微调(Zhao等人,2018年),这是一个非母语的英语语言材料库(Zhao等人,2018年),在不同的培训环境中进行。我们比较了通过多种口音相结合培训的\textbf{(a)}模型与经过培训的仅使用特定口音和\textbf{(b)}不同单一文化模型的结果。我们的实验表明,即使使用少量L2培训数据,甚至没有语言模型,也有望为非母语英语使用者开发ASR模型。我们的模型在零点设置中也非常出色,我们在那里培训多个L2数据集和测试盲人L2测试集。