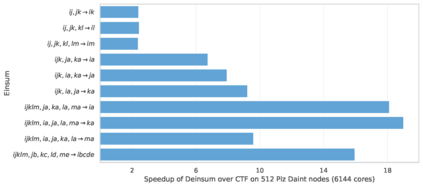
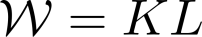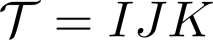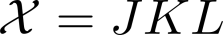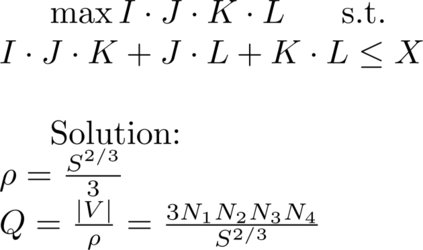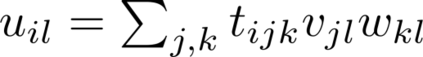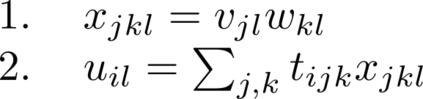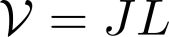Multilinear algebra kernel performance on modern massively-parallel systems is determined mainly by data movement. However, deriving data movement-optimal distributed schedules for programs with many high-dimensional inputs is a notoriously hard problem. State-of-the-art libraries rely on heuristics and often fall back to suboptimal tensor folding and BLAS calls. We present Deinsum, an automated framework for distributed multilinear algebra computations expressed in Einstein notation, based on rigorous mathematical tools to address this problem. Our framework automatically derives data movement-optimal tiling and generates corresponding distributed schedules, further optimizing the performance of local computations by increasing their arithmetic intensity. To show the benefits of our approach, we test it on two important tensor kernel classes: Matricized Tensor Times Khatri-Rao Products and Tensor Times Matrix chains. We show performance results and scaling on the Piz Daint supercomputer, with up to 19x speedup over state-of-the-art solutions on 512 nodes.
翻译:多线性代数内核在现代大规模平行系统中的多线性能主要由数据流动决定。然而,为含有许多高维投入的程式生成数据移动最优化分布时间表是一个臭名昭著的难题。最先进的图书馆依赖于超光学,往往会退回到亚优的极点折叠和 BLAS 调用。我们介绍Deinsum, 这是一个基于严格数学工具的爱因斯坦符号表达的分布式多线性代数计算自动框架,用以解决这一问题。我们的框架自动生成数据移动-最优化的饱和并生成相应的分布时间表,通过提高算术强度进一步优化本地计算绩效。为了展示我们的方法的好处,我们测试了两个重要的格子内核级:数学泰森泰姆时的Khatri-Rao产品和Tensor Tensor Tens 矩阵链。我们展示了业绩结果,并在Piz Daint 超级计算机上提升了规模,在512个节点上超越了状态的解决方案,达到19x速度。