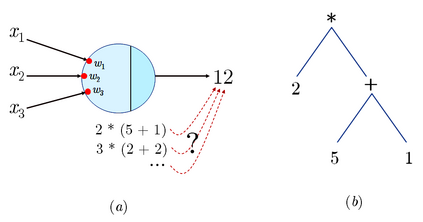
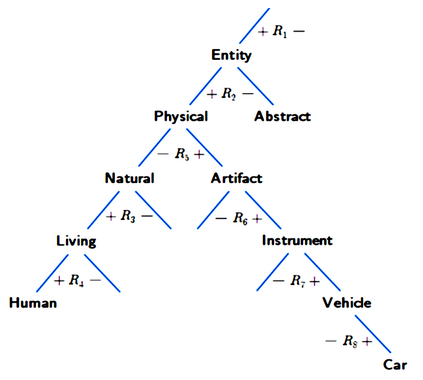
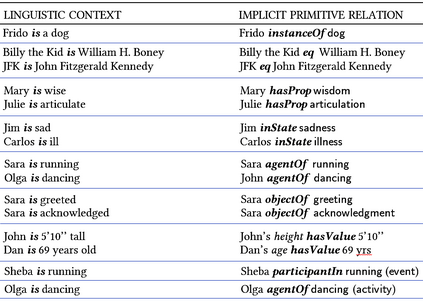
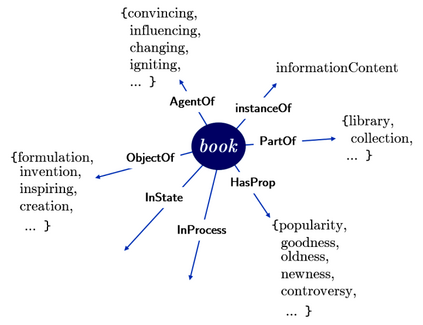
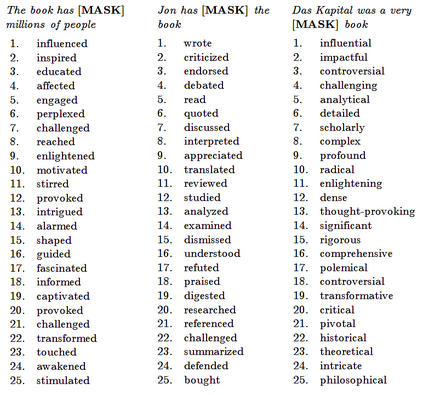
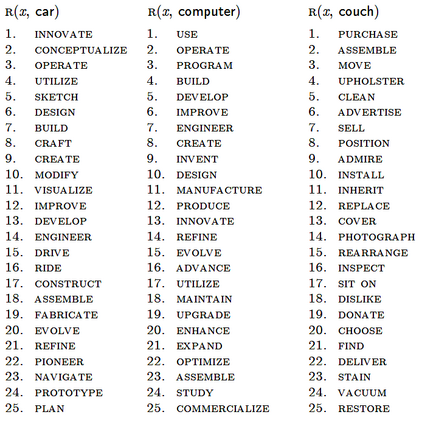
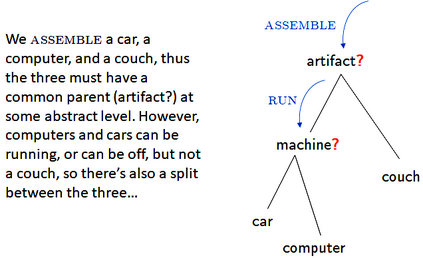
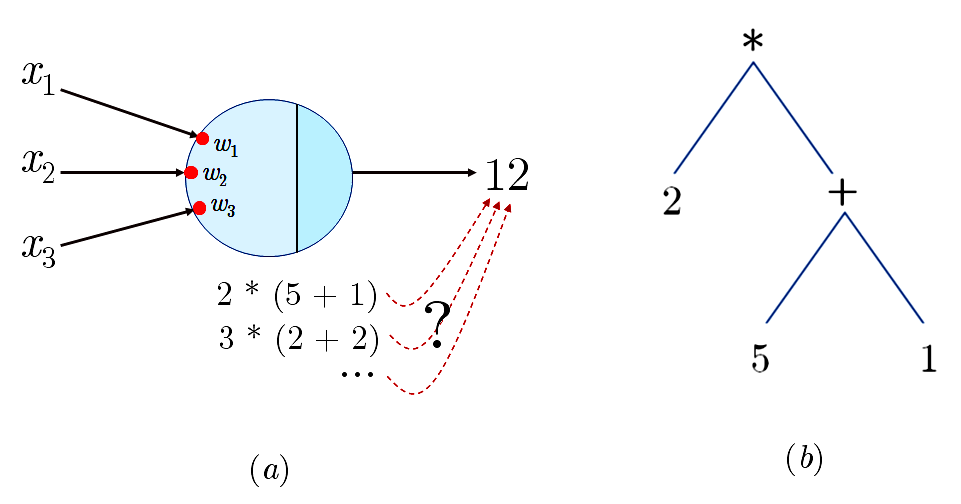
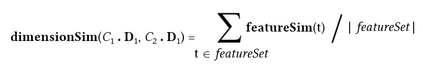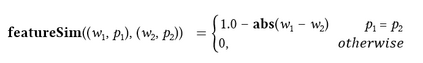Large language models (LLMs) have achieved a milestone that undenia-bly changed many held beliefs in artificial intelligence (AI). However, there remains many limitations of these LLMs when it comes to true language understanding, limitations that are a byproduct of the under-lying architecture of deep neural networks. Moreover, and due to their subsymbolic nature, whatever knowledge these models acquire about how language works will always be buried in billions of microfeatures (weights), none of which is meaningful on its own, making such models hopelessly unexplainable. To address these limitations, we suggest com-bining the strength of symbolic representations with what we believe to be the key to the success of LLMs, namely a successful bottom-up re-verse engineering of language at scale. As such we argue for a bottom-up reverse engineering of language in a symbolic setting. Hints on what this project amounts to have been suggested by several authors, and we discuss in some detail here how this project could be accomplished.
翻译:暂无翻译