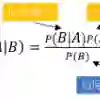
High stakes classification refers to classification problems where erroneously predicting the wrong class is very bad, but assigning "unknown" is acceptable. We make the argument that these problems require us to give multiple unknown classes, to get the most information out of our analysis. With imperfect data we refer to covariates with a large number of missing values, large noise variance, and some errors in the data. The combination of high stakes classification and imperfect data is very common in practice, but it is very difficult to work on using current methods. We present a one-class classifier (OCC) to solve this problem, and we call it NBP. The classifier is based on Naive Bayes, simple to implement, and interpretable. We show that NBP gives both good predictive performance, and works for high stakes classification based on imperfect data. The model we present is quite simple; it is just an OCC based on density estimation. However, we have always felt a big gap between the applied classification problems we have worked on and the theory and models we use for classification, and this model closes that gap. Our main contribution is the motivation for why this model is a good approach, and we hope that this paper will inspire further development down this path.
翻译:暂无翻译