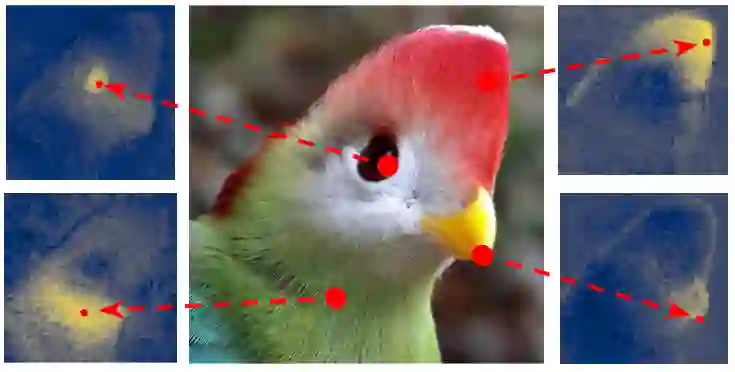
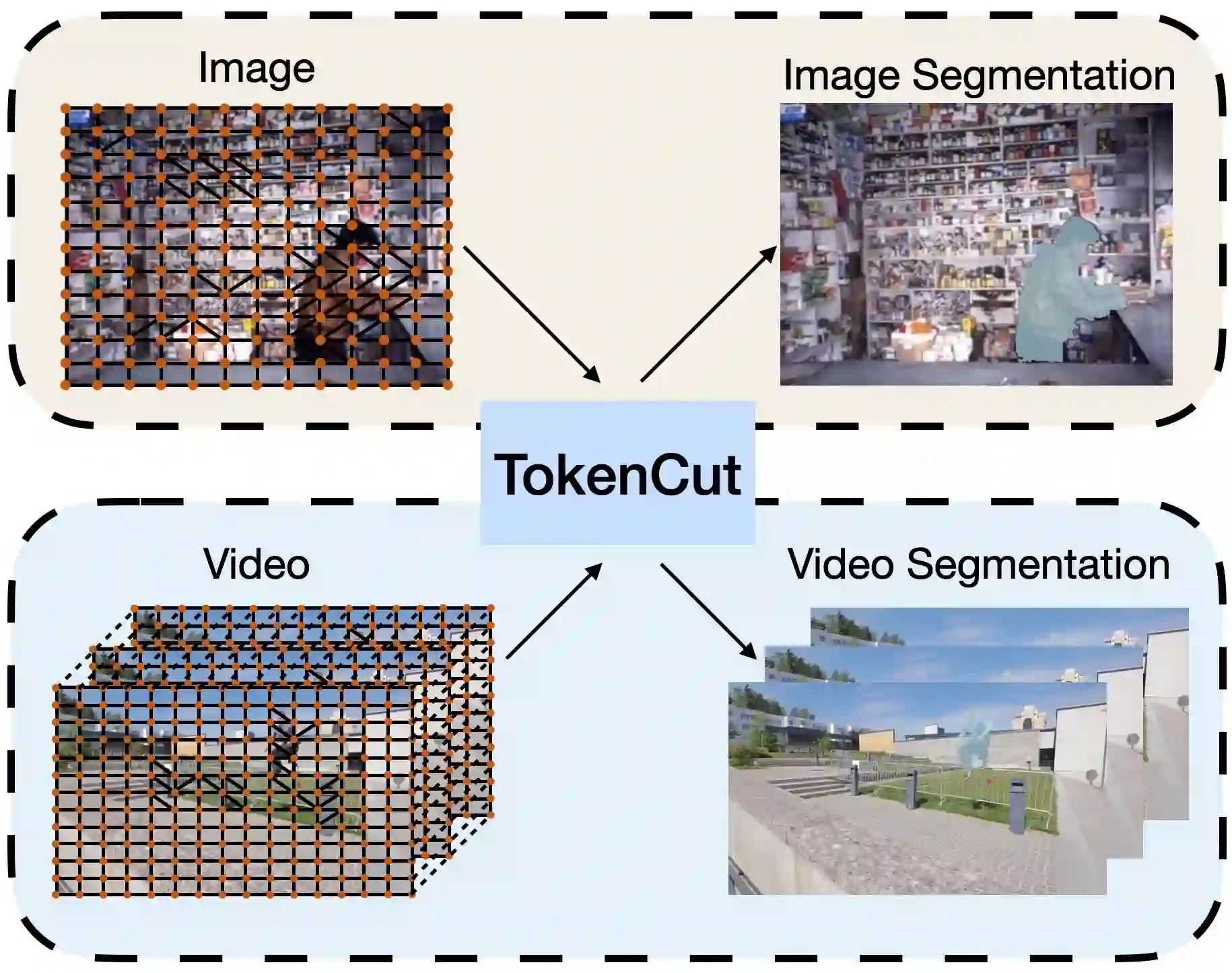
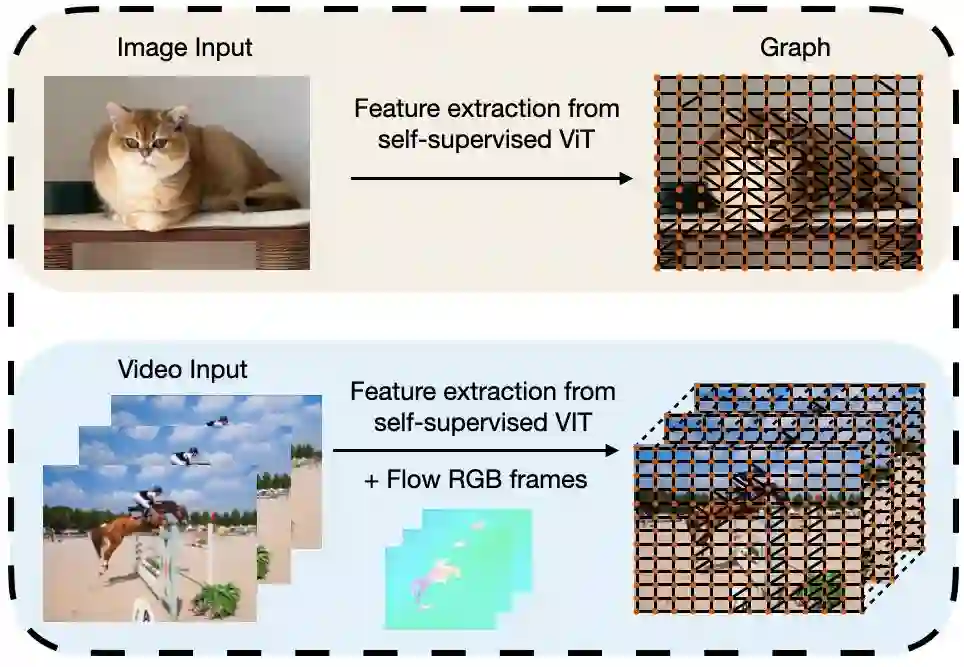
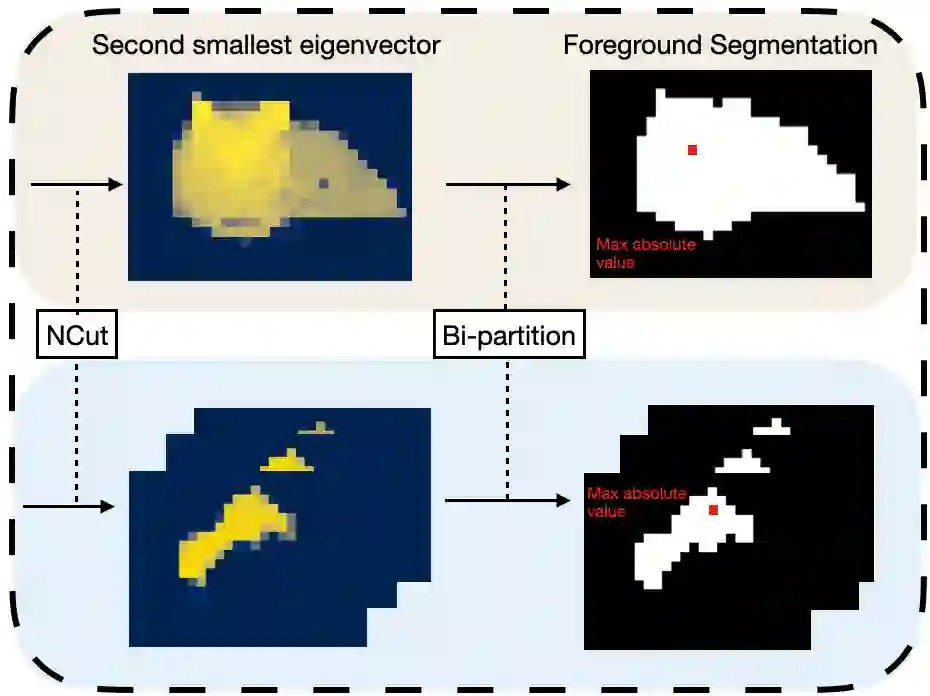
In this paper, we describe a graph-based algorithm that uses the features obtained by a self-supervised transformer to detect and segment salient objects in images and videos. With this approach, the image patches that compose an image or video are organised into a fully connected graph, where the edge between each pair of patches is labeled with a similarity score between patches using features learned by the transformer. Detection and segmentation of salient objects is then formulated as a graph-cut problem and solved using the classical Normalized Cut algorithm. Despite the simplicity of this approach, it achieves state-of-the-art results on several common image and video detection and segmentation tasks. For unsupervised object discovery, this approach outperforms the competing approaches by a margin of 6.1%, 5.7%, and 2.6%, respectively, when tested with the VOC07, VOC12, and COCO20K datasets. For the unsupervised saliency detection task in images, this method improves the score for Intersection over Union (IoU) by 4.4%, 5.6% and 5.2%. When tested with the ECSSD, DUTS, and DUT-OMRON datasets, respectively, compared to current state-of-the-art techniques. This method also achieves competitive results for unsupervised video object segmentation tasks with the DAVIS, SegTV2, and FBMS datasets.
翻译:在本文中, 我们描述一个基于图形的算法, 该算法使用自监督变压器获得的特征探测图像和视频和视频中的突出对象, 并进行分解。 采用这种方法, 构成图像或视频的图像补丁被组织成一个完全连接的图形, 每对补丁的边缘被标记为使用变压器所学特征的补丁之间的类似评分。 然后, 显要对象的检测和分解被设计成一个图形切分问题, 并使用典型的普通化切换算法来解决 。 尽管这一方法简单, 它在多个通用图像和视频的检测和分解任务上取得了最先进的结果。 对于未受监督的发现对象, 这个方法在用 VOC07、 VOC12 和 CO20K 数据集进行测试时, 以6.1% 、 5.7% 和 2.6% 的差差差, 在用 ECSBISSDS、 DUDS 和 5.2 的当前数据SEV 测试时, 也用ECSD- SEVS 和 DSEVS- 的SD- SEVAL, 的 的 方法,, 和 SALUDUDSD- SUD- SUD- SD- SLA- SLS 的 的 的 的 和 的 的 和 的 也实现了 方法, 。