
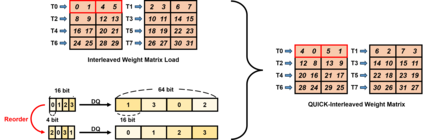
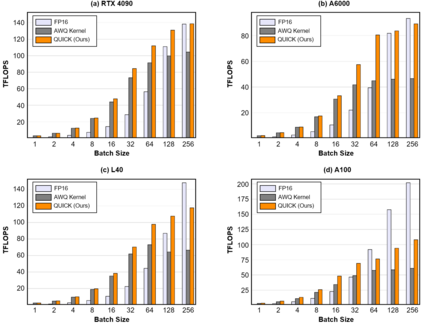
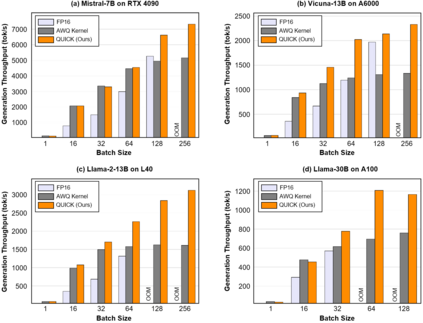
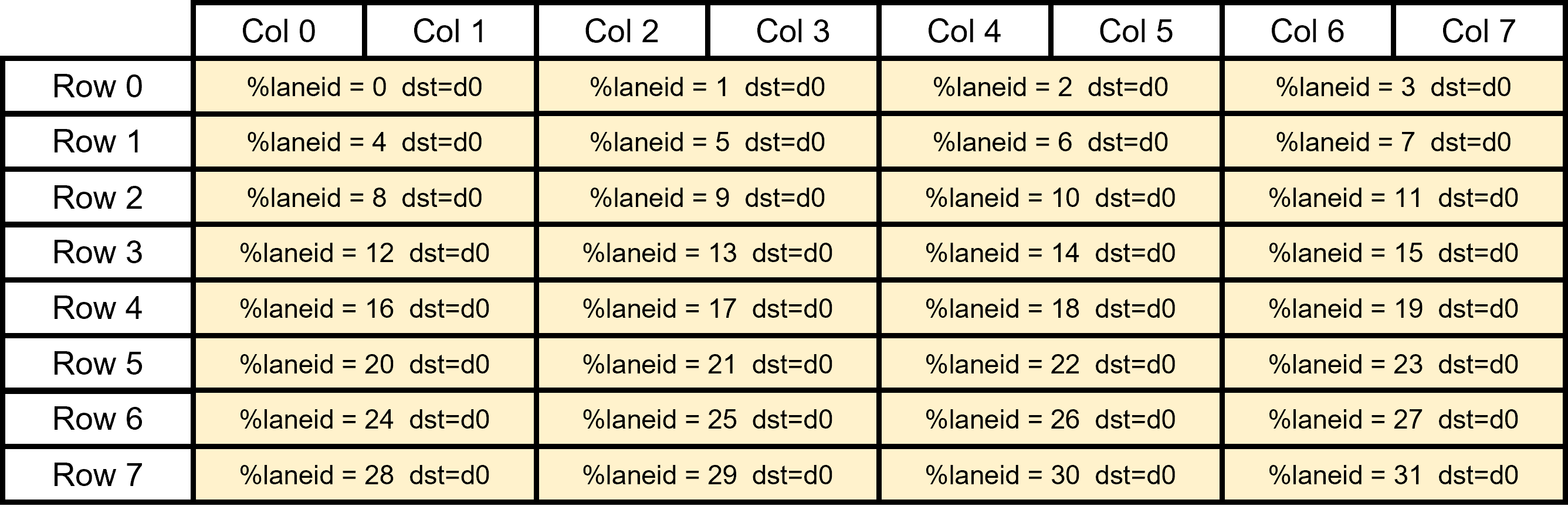
We introduce QUICK, a group of novel optimized CUDA kernels for the efficient inference of quantized Large Language Models (LLMs). QUICK addresses the shared memory bank-conflict problem of state-of-the-art mixed precision matrix multiplication kernels. Our method interleaves the quantized weight matrices of LLMs offline to skip the shared memory write-back after the dequantization. We demonstrate up to 1.91x speedup over existing kernels of AutoAWQ on larger batches and up to 1.94x throughput gain on representative LLM models on various NVIDIA GPU devices.
翻译:暂无翻译
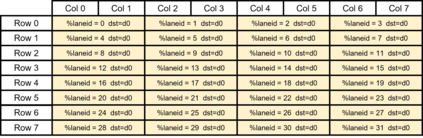
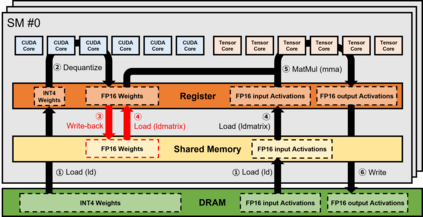
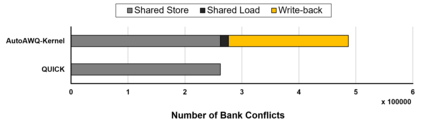
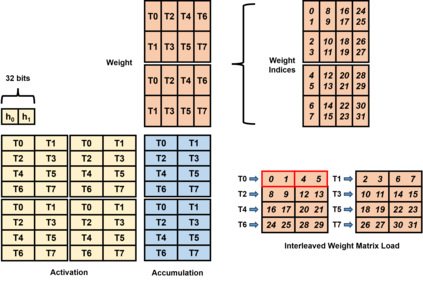

相关内容

大语言模型是基于海量文本数据训练的深度学习模型。它不仅能够生成自然语言文本,还能够深入理解文本含义,处理各种自然语言任务,如文本摘要、问答、翻译等。2023年,大语言模型及其在人工智能领域的应用已成为全球科技研究的热点,其在规模上的增长尤为引人注目,参数量已从最初的十几亿跃升到如今的一万亿。参数量的提升使得模型能够更加精细地捕捉人类语言微妙之处,更加深入地理解人类语言的复杂性。在过去的一年里,大语言模型在吸纳新知识、分解复杂任务以及图文对齐等多方面都有显著提升。随着技术的不断成熟,它将不断拓展其应用范围,为人类提供更加智能化和个性化的服务,进一步改善人们的生活和生产方式。
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
Arxiv
100+阅读 · 2020年2月20日
Arxiv
11+阅读 · 2019年9月8日
Arxiv
40+阅读 · 2019年6月4日
Arxiv
16+阅读 · 2019年5月24日
Arxiv
10+阅读 · 2018年5月10日



相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯
相关论文
Arxiv
100+阅读 · 2020年2月20日
Arxiv
11+阅读 · 2019年9月8日
Arxiv
40+阅读 · 2019年6月4日
Arxiv
16+阅读 · 2019年5月24日
Arxiv
10+阅读 · 2018年5月10日