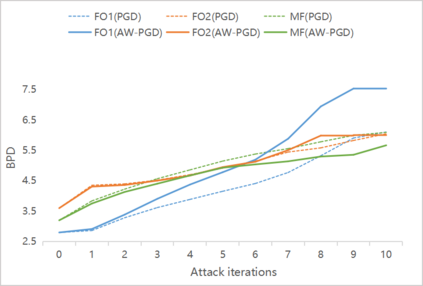
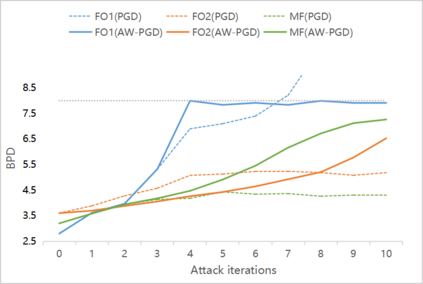
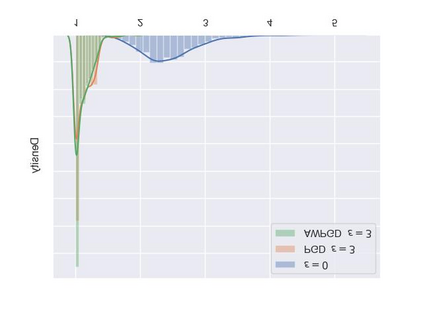
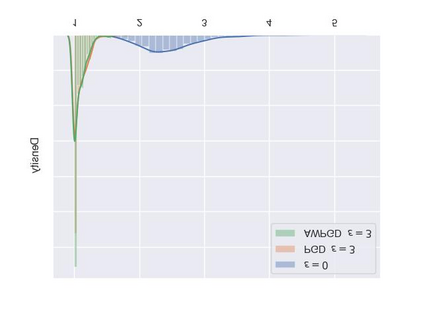
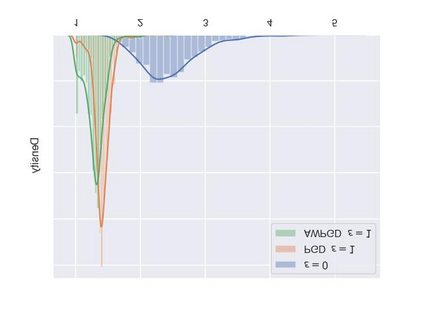
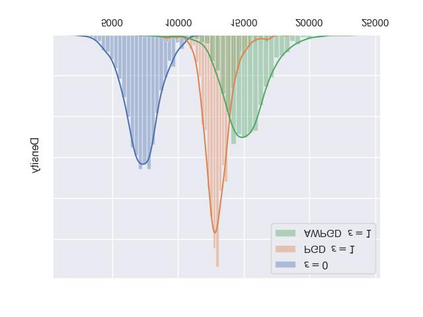
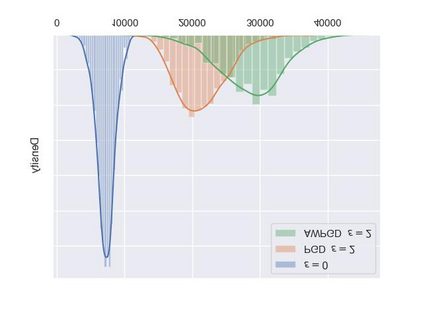
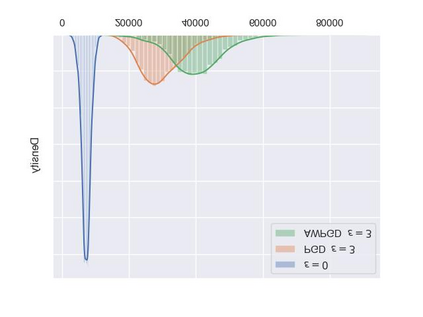
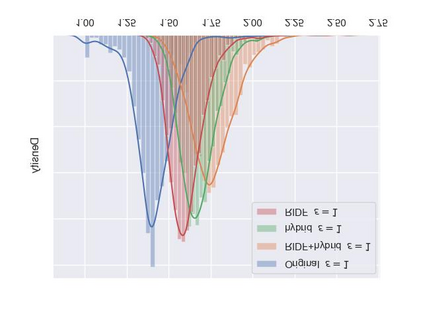
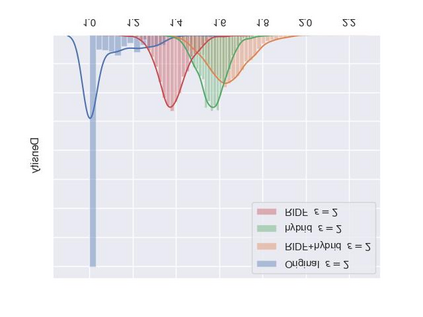
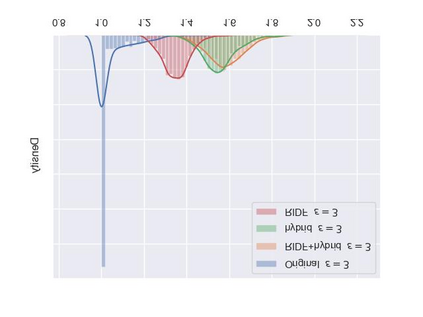
As a probabilistic modeling technique, the flow-based model has demonstrated remarkable potential in the field of lossless compression \cite{idf,idf++,lbb,ivpf,iflow},. Compared with other deep generative models (eg. Autoregressive, VAEs) \cite{bitswap,hilloc,pixelcnn++,pixelsnail} that explicitly model the data distribution probabilities, flow-based models perform better due to their excellent probability density estimation and satisfactory inference speed. In flow-based models, multi-scale architecture provides a shortcut from the shallow layer to the output layer, which significantly reduces the computational complexity and avoid performance degradation when adding more layers. This is essential for constructing an advanced flow-based learnable bijective mapping. Furthermore, the lightweight requirement of the model design in practical compression tasks suggests that flows with multi-scale architecture achieve the best trade-off between coding complexity and compression efficiency.
翻译:作为概率模型技术,流基模型在无损压缩 \ cite{idf, idf++, lbb,ivpf, ifrlow} 领域显示出了显著的潜力。与其他深层基因模型(例如,自动递增, VAEs)相比,该模型(例如,自动递增, VAEs)\ cite{bitswap, hilloc, pixelcnn++, pixelsnail) 明确模拟数据分布概率,流基模型由于其极佳的概率估计和令人满意的推断速度而表现得更好。 在流基模型中,多尺度结构提供了从浅层到输出层的捷径,大大降低了计算复杂性,并在添加更多层时避免了性能退化。这对于构建先进的流基可学习的双向绘图至关重要。此外,模型设计在实际压缩任务中的轻量要求表明,与多尺度结构的流程在编码复杂性和压缩效率之间实现最佳交换。