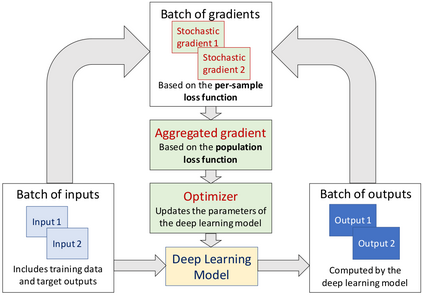
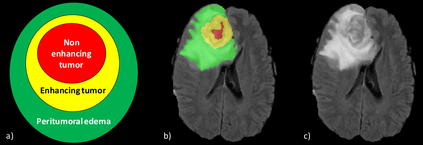
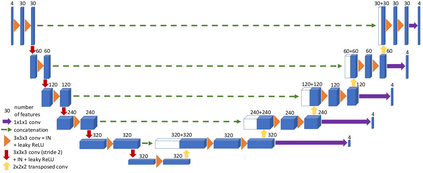
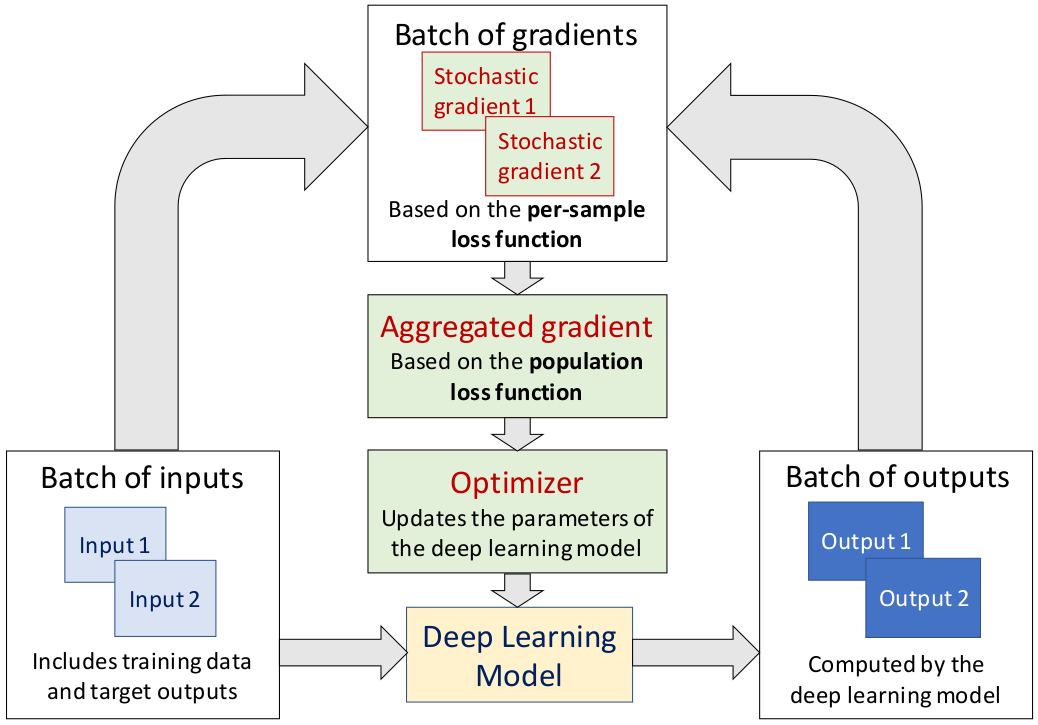
Training a deep neural network is an optimization problem with four main ingredients: the design of the deep neural network, the per-sample loss function, the population loss function, and the optimizer. However, methods developed to compete in recent BraTS challenges tend to focus only on the design of deep neural network architectures, while paying less attention to the three other aspects. In this paper, we experimented with adopting the opposite approach. We stuck to a generic and state-of-the-art 3D U-Net architecture and experimented with a non-standard per-sample loss function, the generalized Wasserstein Dice loss, a non-standard population loss function, corresponding to distributionally robust optimization, and a non-standard optimizer, Ranger. Those variations were selected specifically for the problem of multi-class brain tumor segmentation. The generalized Wasserstein Dice loss is a per-sample loss function that allows taking advantage of the hierarchical structure of the tumor regions labeled in BraTS. Distributionally robust optimization is a generalization of empirical risk minimization that accounts for the presence of underrepresented subdomains in the training dataset. Ranger is a generalization of the widely used Adam optimizer that is more stable with small batch size and noisy labels. We found that each of those variations of the optimization of deep neural networks for brain tumor segmentation leads to improvements in terms of Dice scores and Hausdorff distances. With an ensemble of three deep neural networks trained with various optimization procedures, we achieved promising results on the validation dataset of the BraTS 2020 challenge. Our ensemble ranked fourth out of the 693 registered teams for the segmentation task of the BraTS 2020 challenge.
翻译:深心神经网络培训是一个最优化的问题,它包含四个主要要素:深心神经网络的设计、每类损失功能、人口损失功能和优化。然而,为竞争近期BRATS挑战而开发的方法往往只侧重于深心神经网络结构的设计,而较少注意其他三个方面。在本文中,我们试验的是采用相反的方法。我们坚持一个通用的、最先进的3D U-Net结构,并试验一个非标准的每类损失功能、普遍的瓦塞斯坦 Dice损失、非标准的人口损失网络,与分布强的优化相对应的非标准的人口损失功能,以及非标准优化。这些变化是专门为多级脑网络结构结构设计的,而较少注意其他三个方面。在本文中,我们试验的是采用一个普通的瓦塞斯坦·狄克(Vicestein Dice) 损失是一个每类损失功能,从而能够利用布拉特斯(BRATS)所标的肿瘤区域的等级结构结构结构。 分布强力优化的优化是一种经验风险的概括性风险最小化的描述,即在深度的内分层心脏结构中存在有代表性的细心神经结构,我们所使用的最优化的机能结构结构结构结构结构结构结构的每一个都使用了。