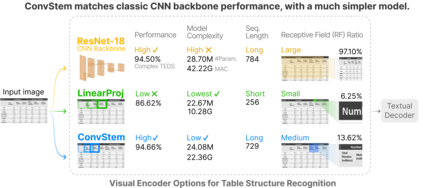
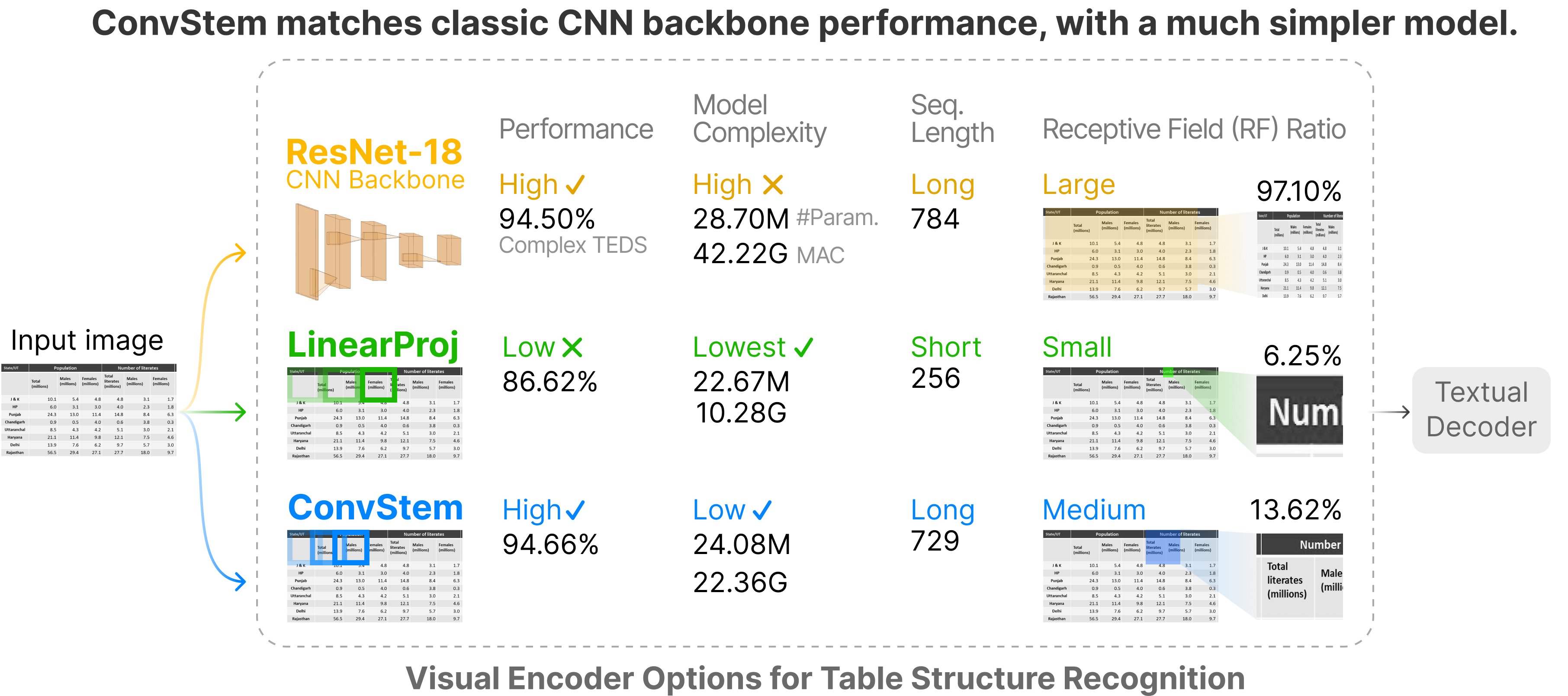
Table structure recognition (TSR) aims to convert tabular images into a machine-readable format, where a visual encoder extracts image features and a textual decoder generates table-representing tokens. Existing approaches use classic convolutional neural network (CNN) backbones for the visual encoder and transformers for the textual decoder. However, this hybrid CNN-Transformer architecture introduces a complex visual encoder that accounts for nearly half of the total model parameters, markedly reduces both training and inference speed, and hinders the potential for self-supervised learning in TSR. In this work, we design a lightweight visual encoder for TSR without sacrificing expressive power. We discover that a convolutional stem can match classic CNN backbone performance, with a much simpler model. The convolutional stem strikes an optimal balance between two crucial factors for high-performance TSR: a higher receptive field (RF) ratio and a longer sequence length. This allows it to "see" an appropriate portion of the table and "store" the complex table structure within sufficient context length for the subsequent transformer. We conducted reproducible ablation studies and open-sourced our code at https://github.com/poloclub/tsr-convstem to enhance transparency, inspire innovations, and facilitate fair comparisons in our domain as tables are a promising modality for representation learning.
翻译:暂无翻译