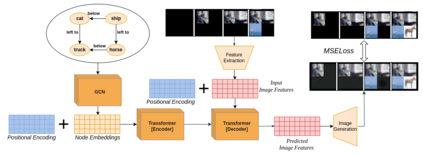
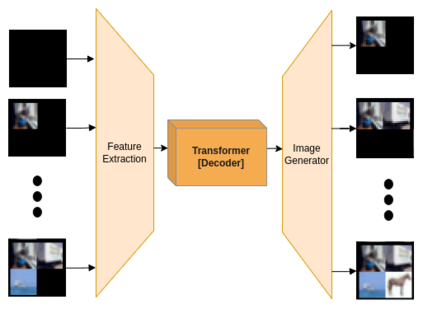
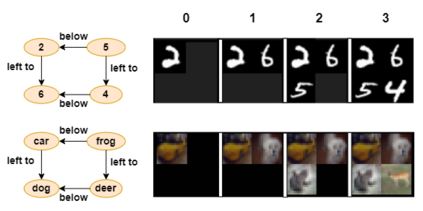
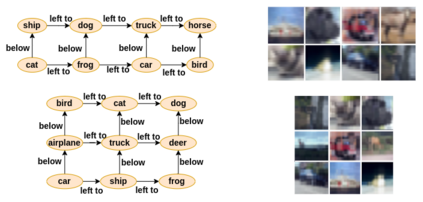
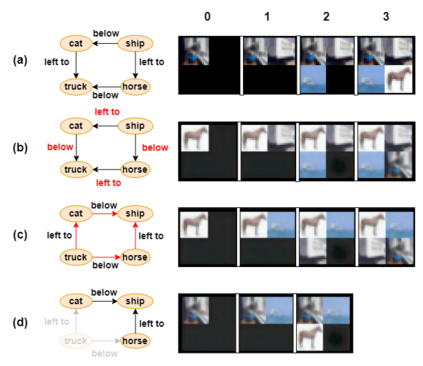
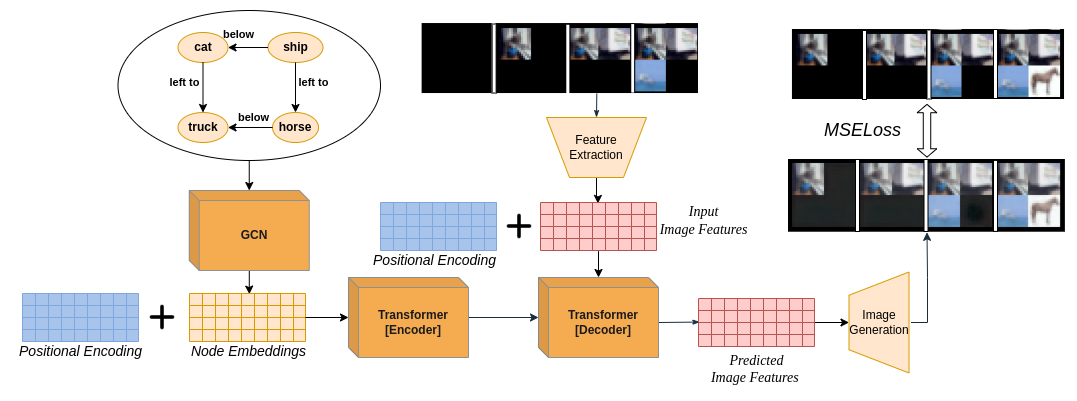
Generating images from semantic visual knowledge is a challenging task, that can be useful to condition the synthesis process in complex, subtle, and unambiguous ways, compared to alternatives such as class labels or text descriptions. Although generative methods conditioned by semantic representations exist, they do not provide a way to control the generation process aside from the specification of constraints between objects. As an example, the possibility to iteratively generate or modify images by manually adding specific items is a desired property that, to our knowledge, has not been fully investigated in the literature. In this work we propose a transformer-based approach conditioned by scene graphs that, conversely to recent transformer-based methods, also employs a decoder to autoregressively compose images, making the synthesis process more effective and controllable. The proposed architecture is composed by three modules: 1) a graph convolutional network, to encode the relationships of the input graph; 2) an encoder-decoder transformer, which autoregressively composes the output image; 3) an auto-encoder, employed to generate representations used as input/output of each generation step by the transformer. Results obtained on CIFAR10 and MNIST images show that our model is able to satisfy semantic constraints defined by a scene graph and to model relations between visual objects in the scene by taking into account a user-provided partial rendering of the desired target.
翻译:从语义直观知识中生成图像是一项艰巨的任务,与类类标签或文本描述等替代品相比,对于以复杂、微妙和毫不含糊的方式对合成过程进行限定是有用的。尽管存在以语义表达方式为条件的基因化方法,但它们并不能提供一种方法来控制生成过程,而除了对对象之间限制的规格之外。举例而言,通过手工添加特定项目来迭代生成或修改图像的可能性是一种理想属性,而文献中并未对此进行充分调查。在这项工作中,我们建议采用一种基于变压器的方法,以场景图为条件,该变压器与最近的变压器基方法相对,还使用一种解析器来自动反向递增变缩图像,使合成过程更加有效和可控制。提议的架构由三个模块组成:1) 图形变动网络,以编码输入图表之间的关系;2) 解析变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变变器,该变变变变变变变变变变变变变变变变变变变变变变变变变变形器,以自动变形变形变形变形变形变形变形变形变换成变形器, 3变形变形变形图图图图图图, 3变变变形变形变变变形变形变形变形变形图,以生成变形变形图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图