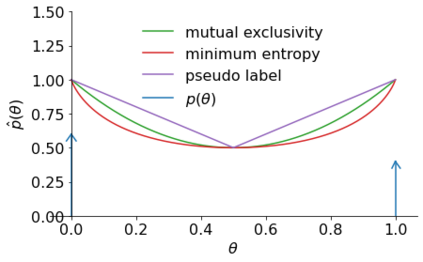
Recent progress has been made in semi-supervised learning (SSL) by combining methods that exploit various aspects of the data distribution, e.g. image augmentation and consistency regularisation, rely on properties of $p(x)$, whereas others, such as entropy minimisation and pseudo-labelling, pertain to the sample-specific label distributions $p(y|x)$. Focusing on the latter, we propose a probabilistic model for discriminative SSL that mirrors its classical generative counterpart, filling a gap in existing semi-supervised learning theory. Under this model, several well-known SSL methods can be interpreted as imposing relaxations of an appropriate prior over learned parameters of $p(y|x)$. The same model extends naturally to neuro-symbolic SSL, often treated as a separate field, in which binary label attributes are subject to logical rules. The model thus also theoretically justifies a family of neuro-symbolic SSL methods and unifies them with standard SSL, taking a step towards bridging the divide between statistical learning and logical reasoning.
翻译:在半监督的学习(SSL)方面,最近取得了进展,将利用数据分布各个方面的方法结合起来,例如图像增强和一致性规范化,依赖于美元(x)的特性,而其他方法,例如最小化和假标签,则与抽样特定标签分配值($p(y ⁇ x)美元)有关。我们以后者为焦点,提出了具有歧视性的SSL的概率模型,该模型反映了其古老的基因化对应方,填补了现有半监督学习理论中的一个空白。在这个模型下,一些众所周知的SSL方法可以被解释为对适当先前超学的美元(y ⁇ x)参数进行放松。同样的模型自然延伸至神经-精神分裂的SSL,通常作为一个单独的字段处理,在其中二元标签属性受逻辑规则制约。因此,该模型从理论上也为神经-典型SLF方法的组合提供了理由,并将它们与标准SSL统一起来,在缩小统计学习与逻辑推理之间的鸿沟方面迈出了一步。