
We give a near-optimal sample-pass trade-off for pure exploration in multi-armed bandits (MABs) via multi-pass streaming algorithms: any streaming algorithm with sublinear memory that uses the optimal sample complexity of $O(\frac{n}{\Delta^2})$ requires $\Omega(\frac{\log{(1/\Delta)}}{\log\log{(1/\Delta)}})$ passes. Here, $n$ is the number of arms and $\Delta$ is the reward gap between the best and the second-best arms. Our result matches the $O(\log(\frac{1}{\Delta}))$-pass algorithm of Jin et al. [ICML'21] (up to lower order terms) that only uses $O(1)$ memory and answers an open question posed by Assadi and Wang [STOC'20].
翻译:暂无翻译
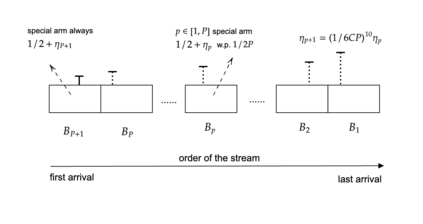
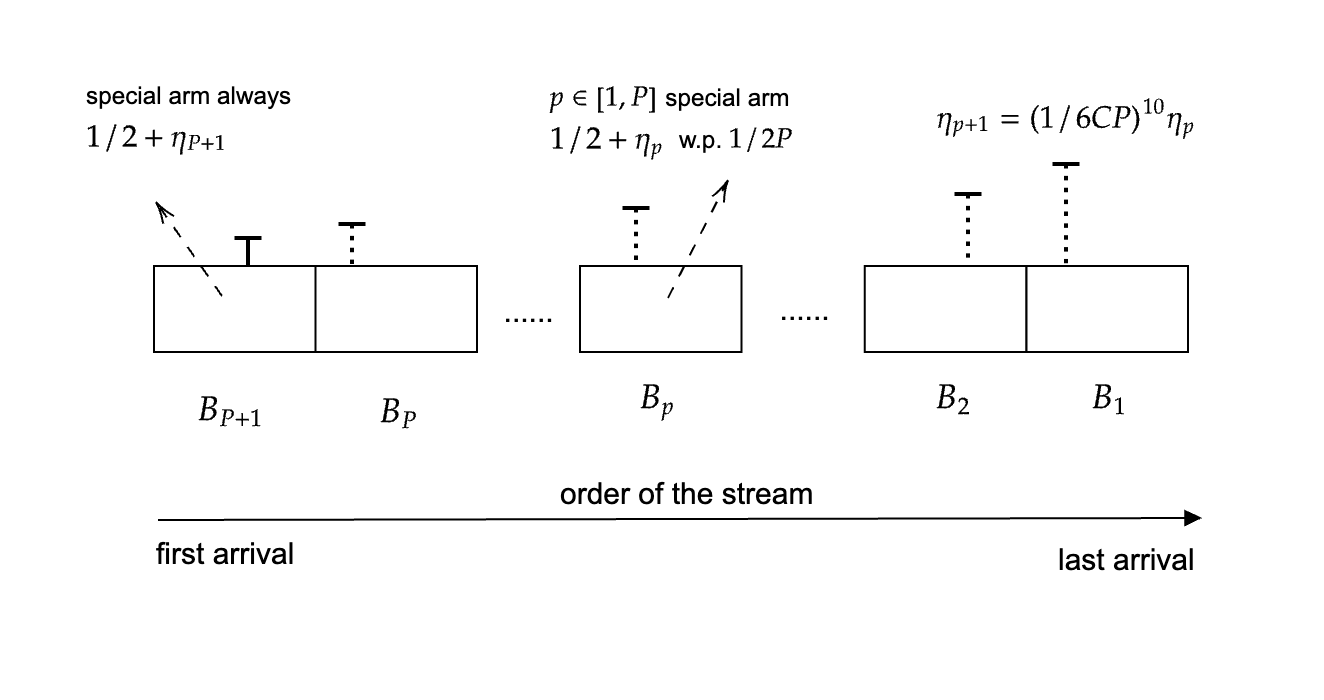
相关内容

专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
Arxiv
11+阅读 · 2021年12月16日
Arxiv
11+阅读 · 2020年10月20日
Arxiv
34+阅读 · 2019年10月24日
Arxiv
40+阅读 · 2019年6月4日
Arxiv
10+阅读 · 2018年3月27日


相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯
相关论文
Arxiv
11+阅读 · 2021年12月16日
Arxiv
11+阅读 · 2020年10月20日
Arxiv
34+阅读 · 2019年10月24日
Arxiv
40+阅读 · 2019年6月4日
Arxiv
10+阅读 · 2018年3月27日