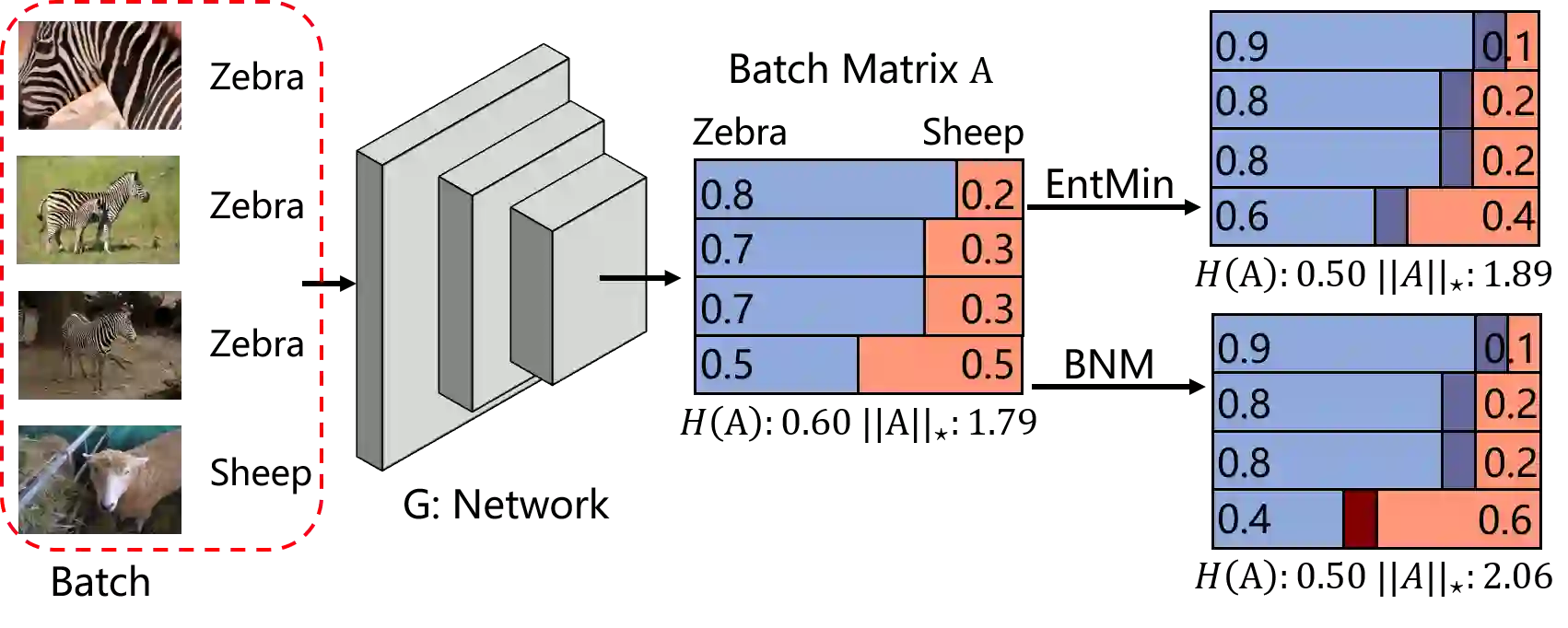
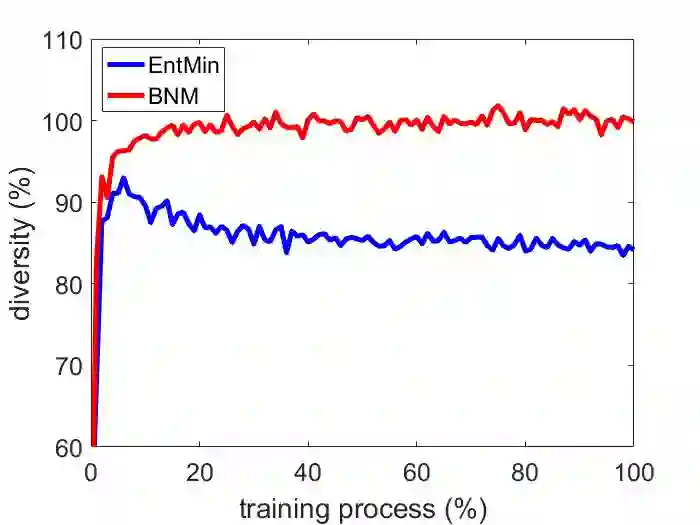
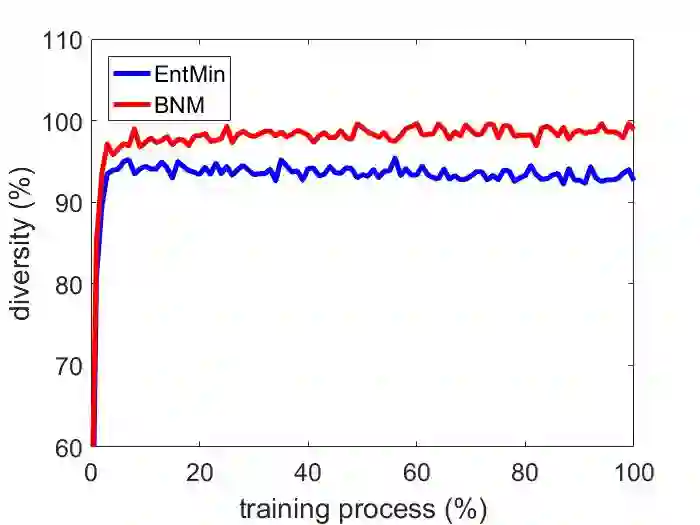
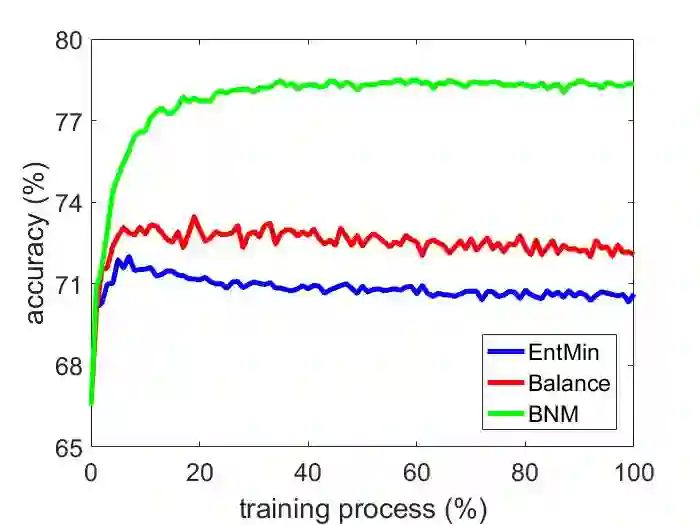
The learning of the deep networks largely relies on the data with human-annotated labels. In some label insufficient situations, the performance degrades on the decision boundary with high data density. A common solution is to directly minimize the Shannon Entropy, but the side effect caused by entropy minimization, i.e., reduction of the prediction diversity, is mostly ignored. To address this issue, we reinvestigate the structure of classification output matrix of a randomly selected data batch. We find by theoretical analysis that the prediction discriminability and diversity could be separately measured by the Frobenius-norm and rank of the batch output matrix. Besides, the nuclear-norm is an upperbound of the Frobenius-norm, and a convex approximation of the matrix rank. Accordingly, to improve both discriminability and diversity, we propose Batch Nuclear-norm Maximization (BNM) on the output matrix. BNM could boost the learning under typical label insufficient learning scenarios, such as semi-supervised learning, domain adaptation and open domain recognition. On these tasks, extensive experimental results show that BNM outperforms competitors and works well with existing well-known methods. The code is available at https://github.com/cuishuhao/BNM.
翻译:深网络的学习在很大程度上依赖于使用带有附加说明的标签的数据。在某些标签不足的情况下,性能在决定边界上降低,数据密度高。一个共同的解决方案是直接将香农环球降低到最低程度,但是由于最小化(即减少预测的多样性)而带来的副作用却大都被忽视。为了解决这个问题,我们重新调查随机选择的数据批量的分类输出矩阵结构。我们通过理论分析发现,预测的分布性和多样性可以通过分批输出矩阵的Frobenius-norm和级别分别测量。此外,核规范是Frobenius-norm的上方,而矩阵级的螺旋近似值。因此,为了改善可变性和多样性,我们提议在输出矩阵上加分核-诺姆最大化(BNM)(BNM) (B) (BNM) (M) (BNM) (BNM) (M) (例如半超超级学习、域适应和开放域识别) (Frobenberus-B(M) (MAG) (M) (M) (M) (MAG) (M) (MDR) (M) (M) (M) (MD) (M) (M) (MD) (MD) (MD) (M) (M) (H) (现有代码良好。