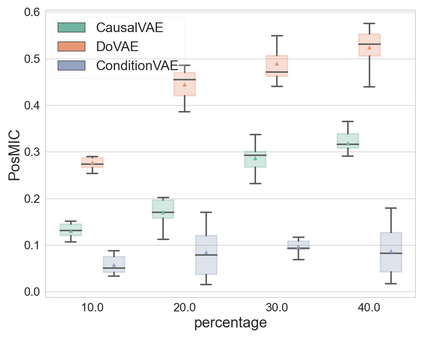
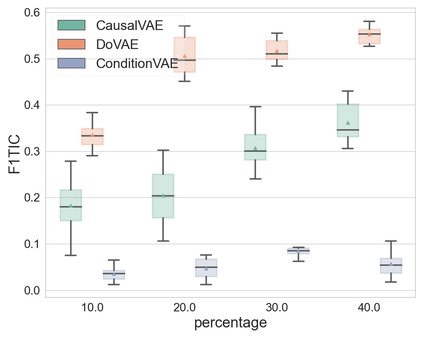
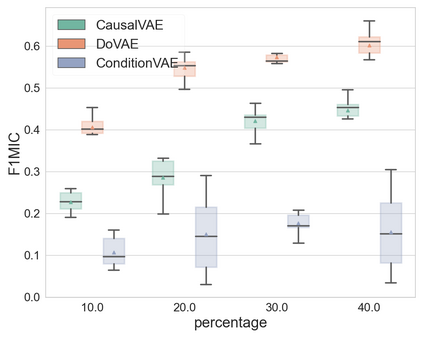
Discovering causal relations among semantic factors is an emergent topic in representation learning. Most causal representation learning (CRL) methods are fully supervised, which is impractical due to costly labeling. To resolve this restriction, weakly supervised CRL methods were introduced. To evaluate CRL performance, four existing datasets, Pendulum, Flow, CelebA(BEARD) and CelebA(SMILE), are utilized. However, existing CRL datasets are limited to simple graphs with few generative factors. Thus we propose two new datasets with a larger number of diverse generative factors and more sophisticated causal graphs. In addition, current real datasets, CelebA(BEARD) and CelebA(SMILE), the originally proposed causal graphs are not aligned with the dataset distributions. Thus, we propose modifications to them.
翻译:暂无翻译