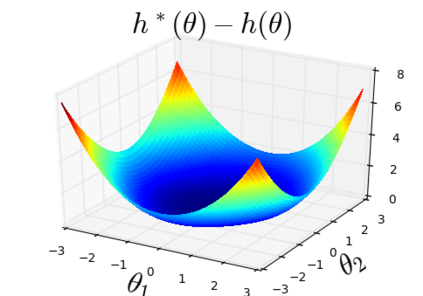
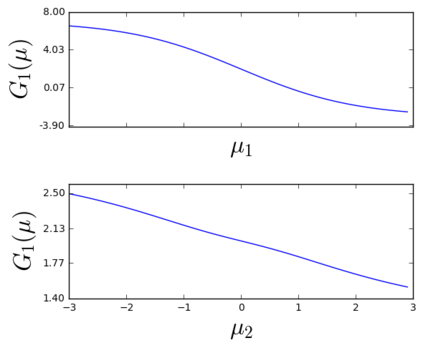
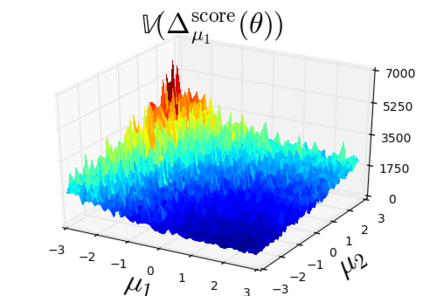
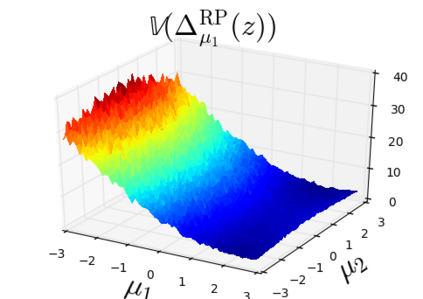
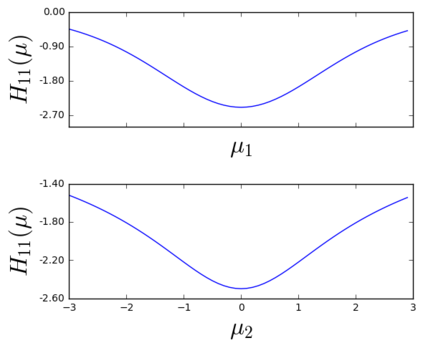
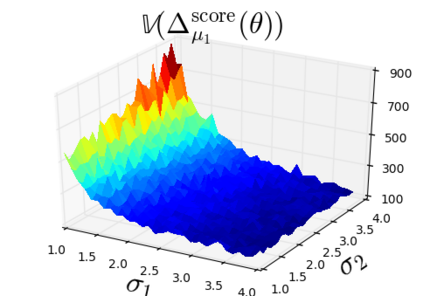
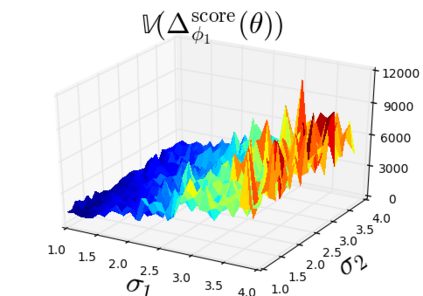
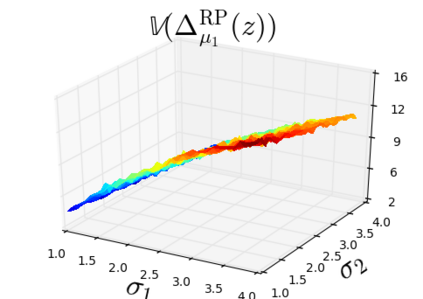
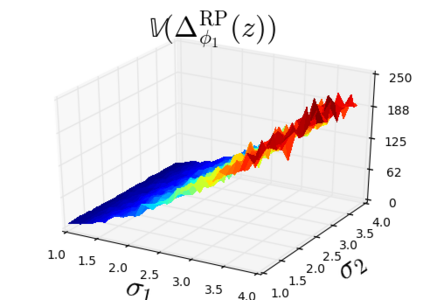
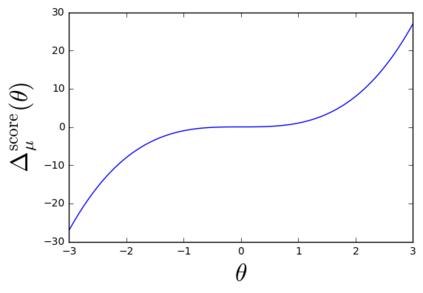
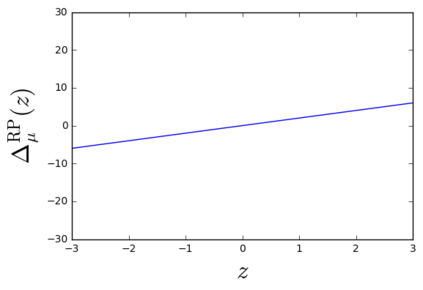
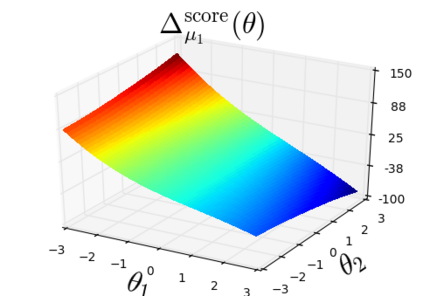
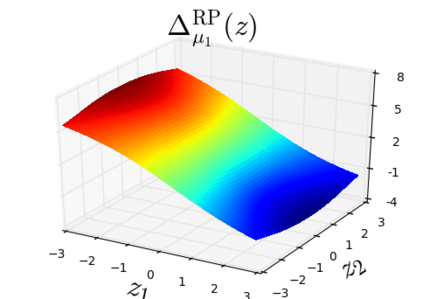
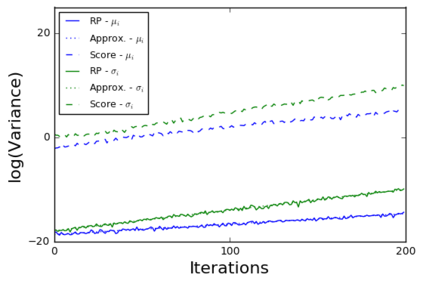
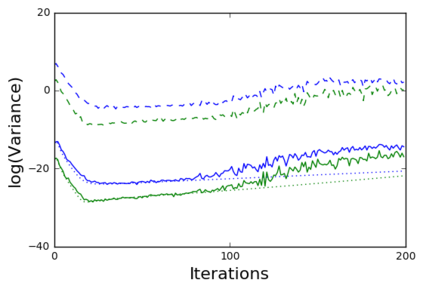
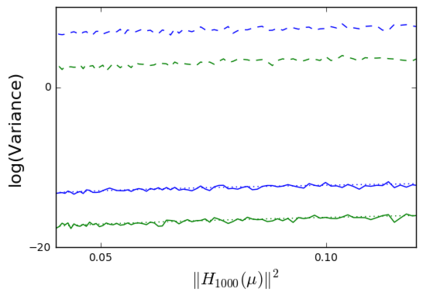
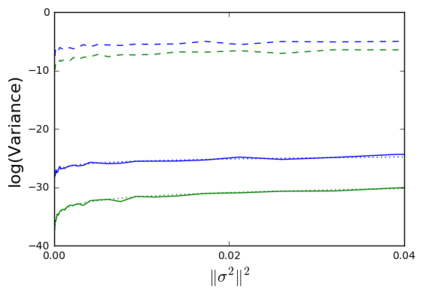
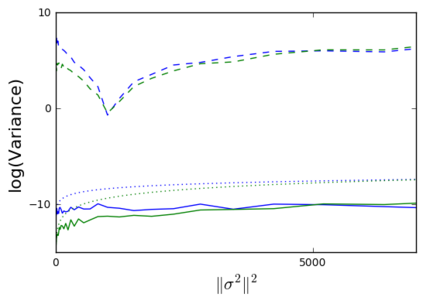
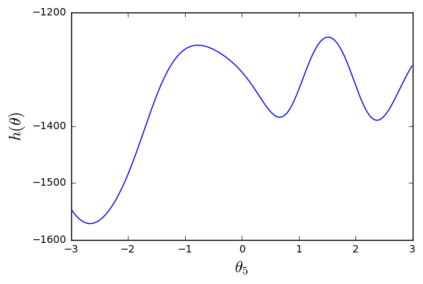
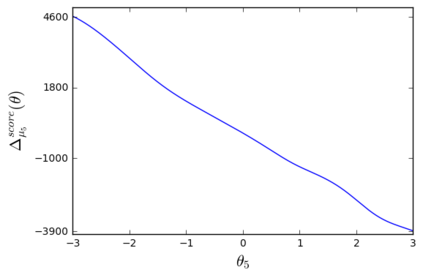
The so-called reparameterization trick is widely used in variational inference as it yields more accurate estimates of the gradient of the variational objective than alternative approaches such as the score function method. The resulting optimization converges much faster as the variance reduction offered by the reparameterization gradient is typically several orders of magnitude. There is overwhelming empirical evidence in the literature showing its success. However, there is relatively little research that explores why the reparameterization gradient is so effective. We explore this under two main simplifying assumptions. First, we assume that the variational approximation is the commonly used mean-field Gaussian density. Second, we assume that the log of the joint density of the model parameter vector and the data is a quadratic function that depends on the variational mean. These assumptions allow us to obtain tractable expressions for the marginal variances of the score function and reparameterization gradient estimators. We also derive lower bounds for the score function marginal variances through Rao-Blackwellization and prove that under our assumptions they are larger than those of the reparameterization trick. Finally, we apply the result of our idealized analysis to examples where the log-joint density is not quadratic, such as in a multinomial logistic regression and a Bayesian neural network with two layers.
翻译:所谓的再校准技巧被广泛用于变差推断,因为它比得分函数法等替代方法更精确地估计变差目标的梯度。 由此产生的优化会比分函数法等替代方法更精确地估计变差目标的梯度。 由此产生的优化会更快地汇集, 因为再校准梯度所提供的差异减少通常是几个数量级。 文献中有压倒性的经验证据表明它取得了成功。 但是, 研究比较少, 探索重新校准梯度为何如此有效。 我们用两个主要简化假设来探讨这一点。 首先, 我们假设变差近点是常用的平均数值高斯密度。 其次, 我们假设模型参数矢量和数据的联合密度记录是一个取决于变差平均值的二次曲线函数函数。 这些假设使我们能够获得分数函数边际差异和再校准梯度估计器的可扩展表达式表达式。 我们还通过Rao- 黑化得出了分数函数边际差的下界限, 并证明在我们假设下, 它们比重新校准的平面图要大得多。 最后, 我们将我们理想化的内基层分析结果应用了以二号为多级回归模型, 。