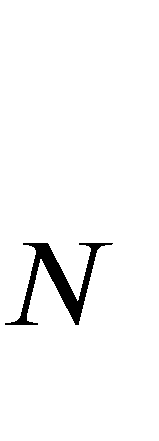Self-healing capability is one of the most critical factors for a resilient distribution system, which requires intelligent agents to automatically perform restorative actions online, including network reconfiguration and reactive power dispatch. These agents should be equipped with a predesigned decision policy to meet real-time requirements and handle highly complex $N-k$ scenarios. The disturbance randomness hampers the application of exploration-dominant algorithms like traditional reinforcement learning (RL), and the agent training problem under $N-k$ scenarios has not been thoroughly solved. In this paper, we propose the imitation learning (IL) framework to train such policies, where the agent will interact with an expert to learn its optimal policy, and therefore significantly improve the training efficiency compared with the RL methods. To handle tie-line operations and reactive power dispatch simultaneously, we design a hybrid policy network for such a discrete-continuous hybrid action space. We employ the 33-node system under $N-k$ disturbances to verify the proposed framework.
翻译:自愈合能力是弹性分配系统最关键的因素之一,它要求智能剂自动在网上实施恢复性行动,包括网络重组和反应式电源发送。这些剂应配备预先设计的决策政策,以满足实时要求并处理高度复杂的美元-千美元情景。扰动随机性阻碍了传统加固学习(RL)等勘探主导算法的应用,而美元-千美元情景下的代理培训问题尚未彻底解决。在本文件中,我们提议了模拟学习(IL)框架,以培训此类政策,使该剂与专家互动,学习最佳政策,从而大大提高培训效率,与RL方法相比。为了同时处理连接线操作和反应式电源发送,我们设计了一个混合混合组合动作空间的混合政策网络。我们使用美元-千元扰动下的33节系统来核查拟议框架。