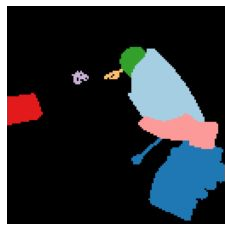
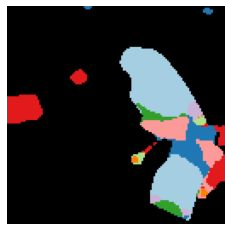
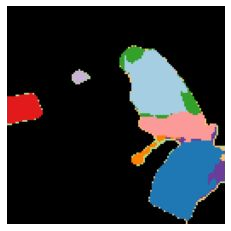
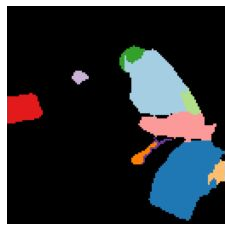
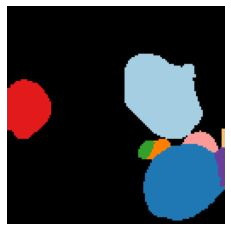
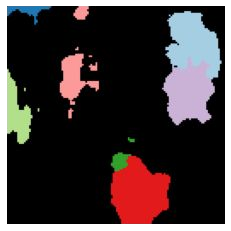
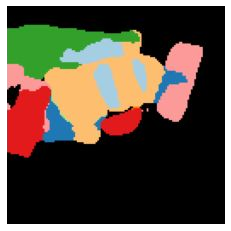
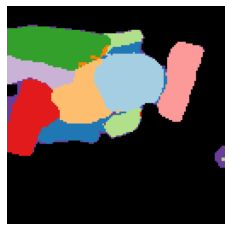
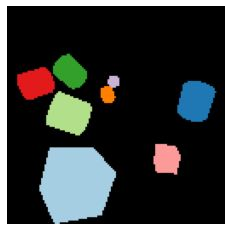
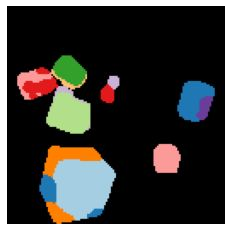
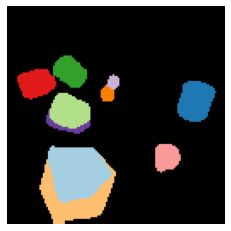
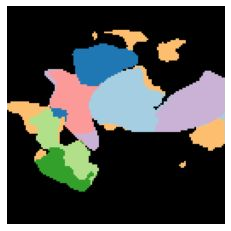
We propose a new approach to learn to segment multiple image objects without manual supervision. The method can extract objects form still images, but uses videos for supervision. While prior works have considered motion for segmentation, a key insight is that, while motion can be used to identify objects, not all objects are necessarily in motion: the absence of motion does not imply the absence of objects. Hence, our model learns to predict image regions that are likely to contain motion patterns characteristic of objects moving rigidly. It does not predict specific motion, which cannot be done unambiguously from a still image, but a distribution of possible motions, which includes the possibility that an object does not move at all. We demonstrate the advantage of this approach over its deterministic counterpart and show state-of-the-art unsupervised object segmentation performance on simulated and real-world benchmarks, surpassing methods that use motion even at test time. As our approach is applicable to variety of network architectures that segment the scenes, we also apply it to existing image reconstruction-based models showing drastic improvement. Project page and code: https://www.robots.ox.ac.uk/~vgg/research/ppmp .
翻译:我们建议一种新的方法, 不经手动监管, 将多个图像对象进行分解。 这种方法可以提取对象, 形成静止图像, 但使用视频进行监控。 虽然先前的工程已经考虑过分解运动, 但关键的洞察力是, 虽然运动可以用来识别对象, 但并非所有物体都必然在运动中: 没有运动并不意味着没有物体。 因此, 我们的模型学会了预测可能含有移动中物体运动模式特征的图像区域。 它没有预测特定动作, 具体动作无法从静止图像中清晰地完成, 而是分布可能的动作, 包括对象可能完全不移动的可能性。 我们展示了这一方法的优势, 在模拟和现实世界基准上展示了最先进的、 艺术的、 不受监督的物体分解功能, 甚至在试验时也超过运动的方法 。 我们的方法适用于分解场的网络结构的多样性, 我们也应用它来分析显示急剧改进的现有图像重建模型 。 项目页和代码: https://www.robots.ox. ac. uk/ ~ v/ respearch/ amping/ coction/ codection.