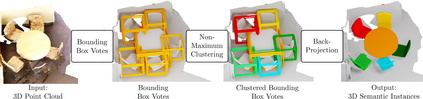
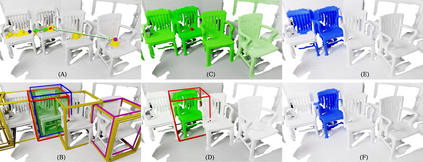
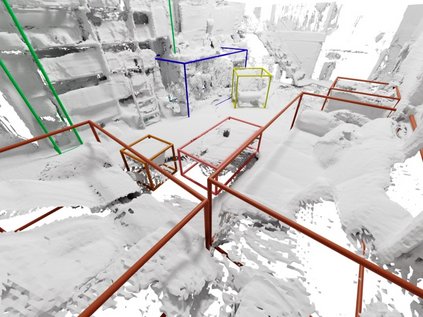
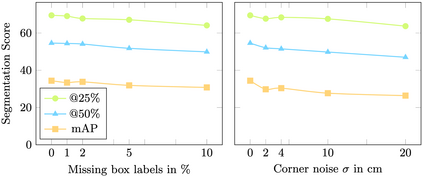
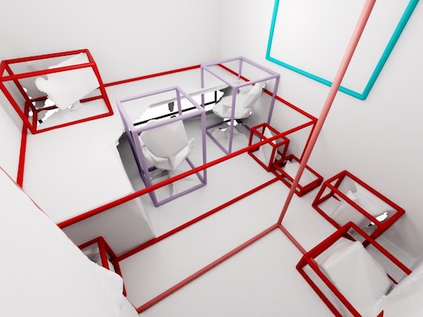
Current 3D segmentation methods heavily rely on large-scale point-cloud datasets, which are notoriously laborious to annotate. Few attempts have been made to circumvent the need for dense per-point annotations. In this work, we look at weakly-supervised 3D instance semantic segmentation. The key idea is to leverage 3D bounding box labels which are easier and faster to annotate. Indeed, we show that it is possible to train dense segmentation models using only weak bounding box labels. At the core of our method, Box2Mask, lies a deep model, inspired by classical Hough voting, that directly votes for bounding box parameters, and a clustering method specifically tailored to bounding box votes. This goes beyond commonly used center votes, which would not fully exploit the bounding box annotations. On ScanNet test, our weakly supervised model attains leading performance among other weakly supervised approaches (+18 mAP50). Remarkably, it also achieves 97% of the performance of fully supervised models. To prove the practicality of our approach, we show segmentation results on the recently released ARKitScenes dataset which is annotated with 3D bounding boxes only, and obtain, for the first time, compelling 3D instance segmentation results.
翻译:目前的 3D 分割法严重依赖大型的点球分解数据集, 这在批注上是十分困难的。 很少有人试图绕过对密集的每点说明的需要。 在这项工作中, 我们查看的是监督不力的 3D 例语义分解法。 关键的想法是利用3D 捆绑框标签, 这些标签更容易和更快到批注。 事实上, 我们显示, 仅使用微弱的捆绑框标签来训练密集的分解模型是可能的。 在我们方法的核心, Box2Mask 中, 是一个深层次的模型, 受经典的Hough投票启发, 直接投票决定约束框参数, 以及专门针对捆绑框票的组合方法。 这超出了常用的中央投票, 无法充分利用捆绑框说明。 在扫描网测试中, 我们受监督薄弱的模型在其它薄弱的监管方法( +18 mAP50) 中取得了领先的性能。 值得注意的是, 在完全监管的模型的性能达到97% 。 为了证明我们的方法的实用性, 我们展示了对约束框框的分解结果, 3RKScionScencesetest 3 获得了最近发行的3 3D 的框的分解结果。