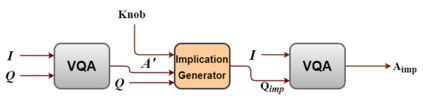
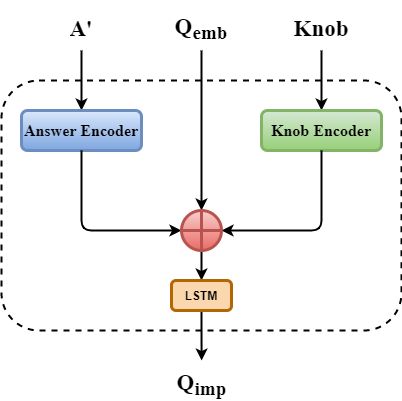
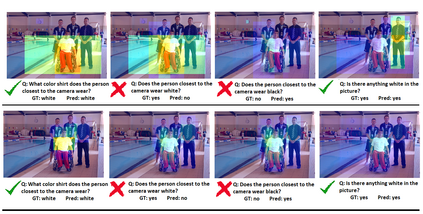
Even though there has been tremendous progress in the field of Visual Question Answering, models today still tend to be inconsistent and brittle. To this end, we propose a model-independent cyclic framework which increases consistency and robustness of any VQA architecture. We train our models to answer the original question, generate an implication based on the answer and then also learn to answer the generated implication correctly. As a part of the cyclic framework, we propose a novel implication generator which can generate implied questions from any question-answer pair. As a baseline for future works on consistency, we provide a new human annotated VQA-Implications dataset. The dataset consists of ~30k questions containing implications of 3 types - Logical Equivalence, Necessary Condition and Mutual Exclusion - made from the VQA v2.0 validation dataset. We show that our framework improves consistency of VQA models by ~15% on the rule-based dataset, ~7% on VQA-Implications dataset and robustness by ~2%, without degrading their performance. In addition, we also quantitatively show improvement in attention maps which highlights better multi-modal understanding of vision and language.
翻译:尽管在视觉问答领域取得了巨大进展,但今天的模型仍然趋向于前后不一和易碎。为此目的,我们提出一个模型独立的循环框架,以提高VQA结构的一致性和稳健性。我们培训模型,以回答最初的问题,产生基于答案的含意,然后学习正确回答产生的含意。作为循环框架的一部分,我们提议一个新颖的影响生成器,它可以从任何问答中产生隐含的问题。作为未来一致性工作的基线,我们提供了一个新的人类附加注释的VQA-副产品数据集。数据集由~30k个问题组成,其中含有三种类型的影响:逻辑等同、必要的共性和相互排斥,这些影响来自VQA v2.0验证数据集。我们指出,我们的框架提高了VQA模型的一致性,在基于规则的数据集上提高了15%,在VQA-附加数据设置上提高了7%,在不贬损其性能的情况下提高了数据的可靠性。此外,我们从数量角度上展示了更好的关注度,在多语言的地图上也显示了更好的关注度。