
题目:DualVD: An Adaptive Dual Encoding Model for Deep Visual Understanding in Visual Dialogue
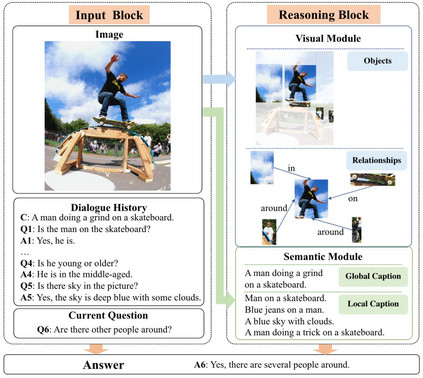
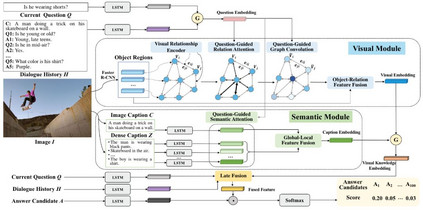
摘要: 近年来,结合视觉和语言的跨媒体人工智能技术取得了很大进展。其中,视觉对话任务要求模型同时具备推理、定位、语言表述等能力,对跨媒体智能提出了更大挑战。本文介绍了中科院信工所于静等的论文《DualVD: An Adaptive Dual Encoding Model for Deep Visual Understanding in Visual Dialogue》(AAAI 2020),该文针对视觉对话中涉及的图像内容范围广、多视角理解困难的问题,提出一种用于刻画图像视觉和语义信息的自适应双向编码模型——DualVD,从视觉目标、视觉关系、高层语义等多层面信息中自适应捕获回答问题的依据,同时通过可视化结果揭示不同信息源对于回答问题的贡献,具有较强的可解释性。该论文是和阿德莱德大学、北京航空航天大学、微软亚洲研究院共同完成。
成为VIP会员查看完整内容
相关内容

中国科学院信息工程研究所是2011年批准成立的中国科学院直属科研机构。研究所按照“软硬兼修,矛盾兼容,开合有法,张弛有度”的办所方针,秉承“打造一流平台,集聚一流人才,支撑国家需求,引领学科发展,努力成为国家在信息工程领域的战略科技力量”的组织目标,面向国家战略需求,在信息安全科技领域,开展基础理论与前沿技术研究,开发应用性技术与系统,为国家信息化进程提供核心关键技术支撑与系统解决方案。 官网地址:http://www.iie.ac.cn/
专知会员服务
58+阅读 · 2019年12月2日
Arxiv
7+阅读 · 2018年5月24日




相关VIP内容
专知会员服务
58+阅读 · 2019年12月2日
相关资讯
相关论文
Arxiv
7+阅读 · 2018年5月24日