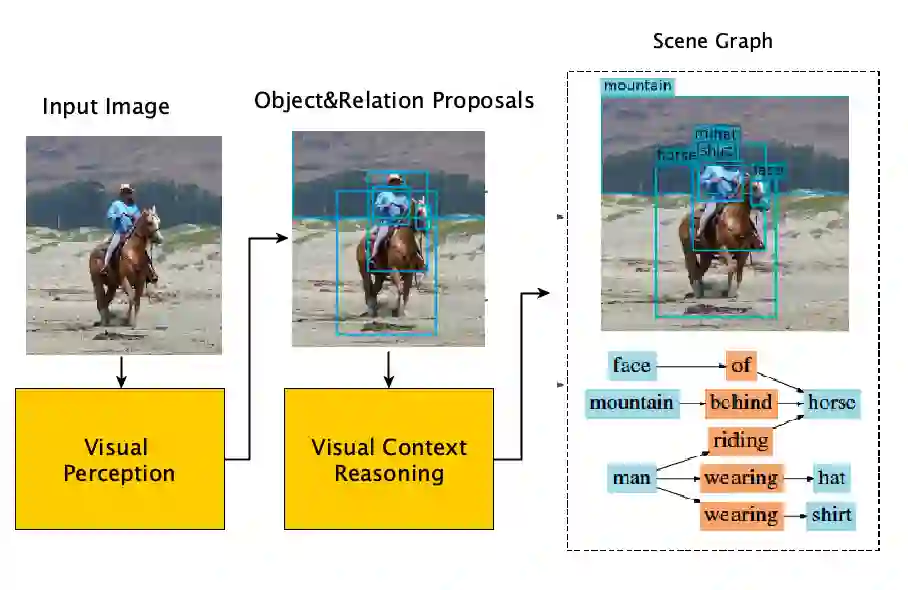
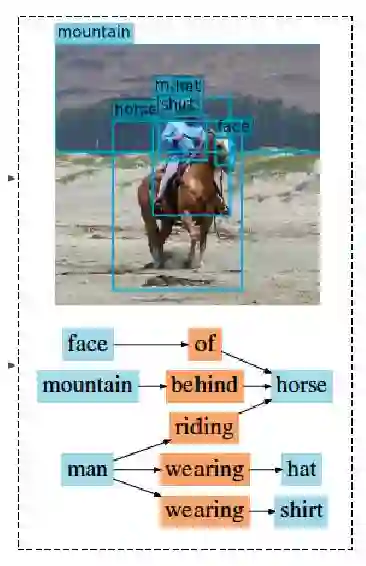
As a structured prediction task, scene graph generation aims to build a visually-grounded scene graph to explicitly model objects and their relationships in an input image. Currently, the mean field variational Bayesian framework is the de facto methodology used by the existing methods, in which the unconstrained inference step is often implemented by a message passing neural network. However, such formulation fails to explore other inference strategies, and largely ignores the more general constrained optimization models. In this paper, we present a constrained structure learning method, for which an explicit constrained variational inference objective is proposed. Instead of applying the ubiquitous message-passing strategy, a generic constrained optimization method - entropic mirror descent - is utilized to solve the constrained variational inference step. We validate the proposed generic model on various popular scene graph generation benchmarks and show that it outperforms the state-of-the-art methods.
翻译:作为一种结构化的预测任务,场景图生成的目的是建立一个直观的场景图,以在输入图像中明确模拟物体及其关系。目前,平均的实地变异贝叶西亚框架是现有方法采用的实际方法,其中无限制的推论步骤往往由传递信息的神经网络实施。然而,这种提法未能探索其他推论战略,而且基本上忽略了更为普遍的制约优化模型。在本文中,我们提出了一个有限制的结构学习方法,为此提出了明确限制的变异推论目标。我们不是采用无处不在的信息传递战略,而是采用通用的限制性优化方法(映射镜底)来解决受限制的变异推论步骤。我们验证了各种流行图像生成基准上的拟议通用模型,并表明该模型优于最先进的方法。