【论文推荐】最新六篇视觉问答相关论文—鲁棒性分析、虚拟意象、双曲注意力网络、R-VQA、关系推理、双线性注意力网络
【导读】专知内容组为大家推出最新六篇视觉问答(Visual Question Answering, VQA)相关论文,欢迎查看!
1.Robustness Analysis of Visual QA Models by Basic Questions(基于基本问题的视觉问答模型的鲁棒性分析)
作者:Jia-Hong Huang,Cuong Duc Dao,Modar Alfadly,C. Huck Yang,Bernard Ghanem
Accepted by CVPR 2018 VQA Challenge and Visual Dialog Workshop.
机构:King Abdullah University of Science and Technology
摘要:Visual Question Answering (VQA) models should have both high robustness and accuracy. Unfortunately, most of the current VQA research only focuses on accuracy because there is a lack of proper methods to measure the robustness of VQA models. There are two main modules in our algorithm. Given a natural language question about an image, the first module takes the question as input and then outputs the ranked basic questions, with similarity scores, of the main given question. The second module takes the main question, image and these basic questions as input and then outputs the text-based answer of the main question about the given image. We claim that a robust VQA model is one, whose performance is not changed much when related basic questions as also made available to it as input. We formulate the basic questions generation problem as a LASSO optimization, and also propose a large scale Basic Question Dataset (BQD) and Rscore (novel robustness measure), for analyzing the robustness of VQA models. We hope our BQD will be used as a benchmark for to evaluate the robustness of VQA models, so as to help the community build more robust and accurate VQA models.
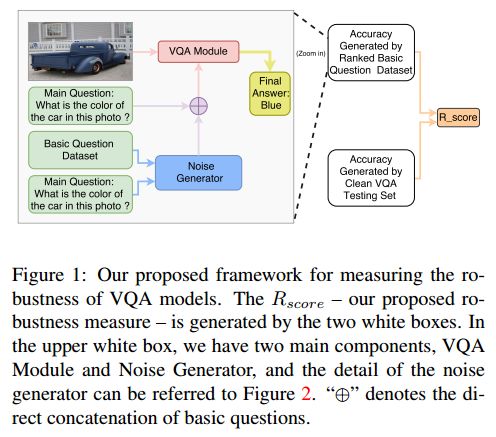
期刊:arXiv, 2018年5月26日
网址:
http://www.zhuanzhi.ai/document/35ddf406a2846d3e3fb320b34cca0b02
2.Think Visually: Question Answering through Virtual Imagery(Think Visually:通过虚拟意象回答问题)
作者:Ankit Goyal,Jian Wang,Jia Deng
Accepted in ACL 2018
机构:University of Michigan
摘要:In this paper, we study the problem of geometric reasoning in the context of question-answering. We introduce Dynamic Spatial Memory Network (DSMN), a new deep network architecture designed for answering questions that admit latent visual representations. DSMN learns to generate and reason over such representations. Further, we propose two synthetic benchmarks, FloorPlanQA and ShapeIntersection, to evaluate the geometric reasoning capability of QA systems. Experimental results validate the effectiveness of our proposed DSMN for visual thinking tasks.
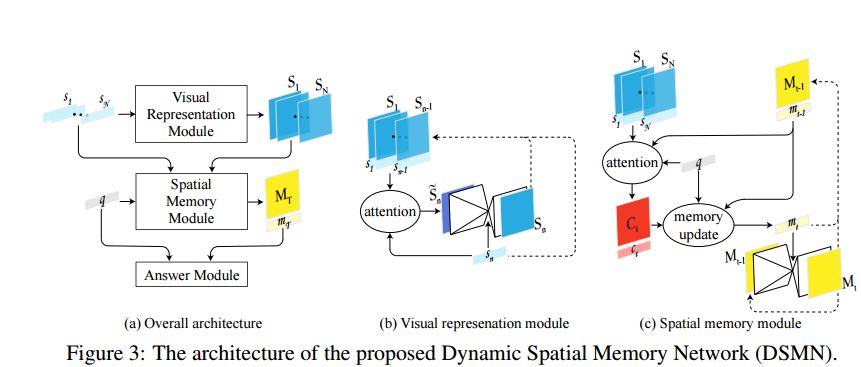
期刊:arXiv, 2018年5月25日
网址:
http://www.zhuanzhi.ai/document/c27a22e67010babbcaf4bd9b9b3cef00
3.Hyperbolic Attention Networks(双曲注意力网络)
作者:Caglar Gulcehre,Misha Denil,Mateusz Malinowski,Ali Razavi,Razvan Pascanu,Karl Moritz Hermann,Peter Battaglia,Victor Bapst,David Raposo,Adam Santoro,Nando de Freitas
机构:Cyprus University of Technology
摘要:We introduce hyperbolic attention networks to endow neural networks with enough capacity to match the complexity of data with hierarchical and power-law structure. A few recent approaches have successfully demonstrated the benefits of imposing hyperbolic geometry on the parameters of shallow networks. We extend this line of work by imposing hyperbolic geometry on the activations of neural networks. This allows us to exploit hyperbolic geometry to reason about embeddings produced by deep networks. We achieve this by re-expressing the ubiquitous mechanism of soft attention in terms of operations defined for hyperboloid and Klein models. Our method shows improvements in terms of generalization on neural machine translation, learning on graphs and visual question answering tasks while keeping the neural representations compact.
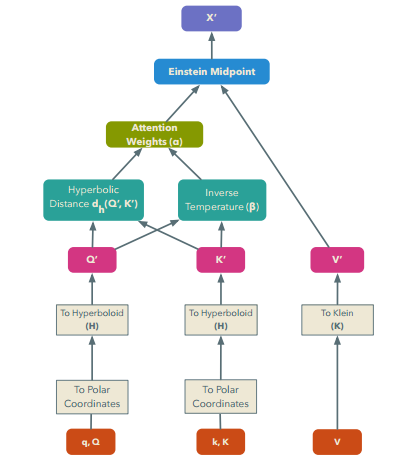
期刊:arXiv, 2018年5月25日
网址:
http://www.zhuanzhi.ai/document/969cbeaaf672845e6f2e4ad21f35200f
4.R-VQA: Learning Visual Relation Facts with Semantic Attention for Visual Question Answering(R-VQA: 用于回答视觉问题的视觉关系事实和语义注意力)
作者:Pan Lu,Lei Ji,Wei Zhang,Nan Duan,Ming Zhou,Jianyong Wang
accepted in SIGKDD 2018
机构:Tsinghua University,Microsoft Corporation,East China Normal University
摘要:Recently, Visual Question Answering (VQA) has emerged as one of the most significant tasks in multimodal learning as it requires understanding both visual and textual modalities. Existing methods mainly rely on extracting image and question features to learn their joint feature embedding via multimodal fusion or attention mechanism. Some recent studies utilize external VQA-independent models to detect candidate entities or attributes in images, which serve as semantic knowledge complementary to the VQA task. However, these candidate entities or attributes might be unrelated to the VQA task and have limited semantic capacities. To better utilize semantic knowledge in images, we propose a novel framework to learn visual relation facts for VQA. Specifically, we build up a Relation-VQA (R-VQA) dataset based on the Visual Genome dataset via a semantic similarity module, in which each data consists of an image, a corresponding question, a correct answer and a supporting relation fact. A well-defined relation detector is then adopted to predict visual question-related relation facts. We further propose a multi-step attention model composed of visual attention and semantic attention sequentially to extract related visual knowledge and semantic knowledge. We conduct comprehensive experiments on the two benchmark datasets, demonstrating that our model achieves state-of-the-art performance and verifying the benefit of considering visual relation facts.
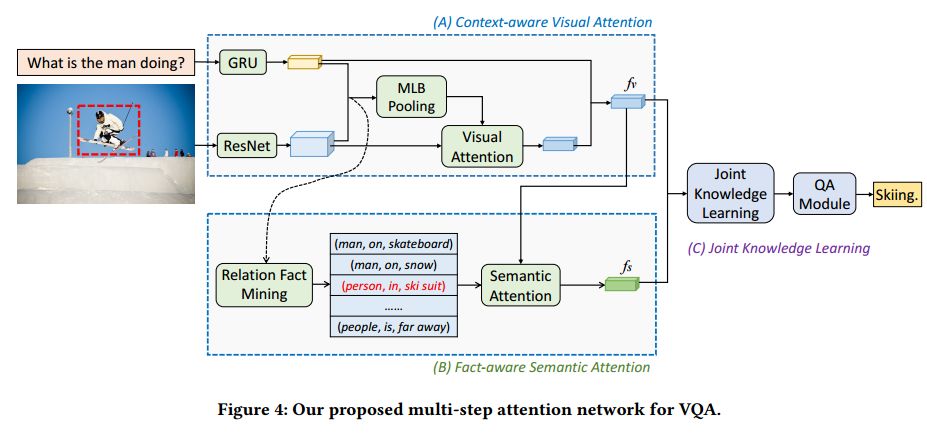
期刊:arXiv, 2018年5月24日
网址:
http://www.zhuanzhi.ai/document/0cd915a5bf0d98cfd8529eb6addf2e44
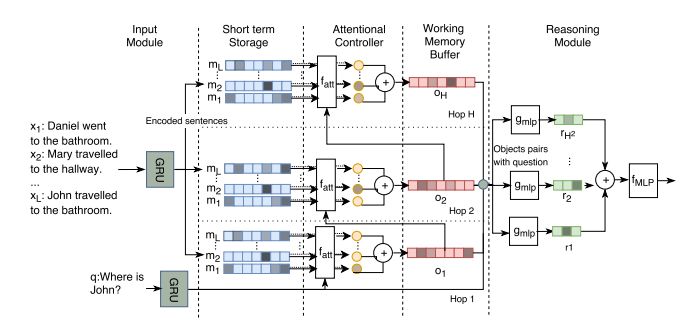
5.Working Memory Networks: Augmenting Memory Networks with a Relational Reasoning Module(Working Memory Networks: 关系推理模块扩展的记忆网络)
作者:Juan Pavez,Héctor Allende,Héctor Allende-Cid
Published in ACL 2018.
机构:Federico Santa Mar´ıa Technical University,Pont´ıfica Universidad Catolica
摘要:During the last years, there has been a lot of interest in achieving some kind of complex reasoning using deep neural networks. To do that, models like Memory Networks (MemNNs) have combined external memory storages and attention mechanisms. These architectures, however, lack of more complex reasoning mechanisms that could allow, for instance, relational reasoning. Relation Networks (RNs), on the other hand, have shown outstanding results in relational reasoning tasks. Unfortunately, their computational cost grows quadratically with the number of memories, something prohibitive for larger problems. To solve these issues, we introduce the Working Memory Network, a MemNN architecture with a novel working memory storage and reasoning module. Our model retains the relational reasoning abilities of the RN while reducing its computational complexity from quadratic to linear. We tested our model on the text QA dataset bAbI and the visual QA dataset NLVR. In the jointly trained bAbI-10k, we set a new state-of-the-art, achieving a mean error of less than 0.5%. Moreover, a simple ensemble of two of our models solves all 20 tasks in the joint version of the benchmark.
期刊:arXiv, 2018年5月24日
网址:
http://www.zhuanzhi.ai/document/bc1dab7f46b61eda5b5fc14457761243
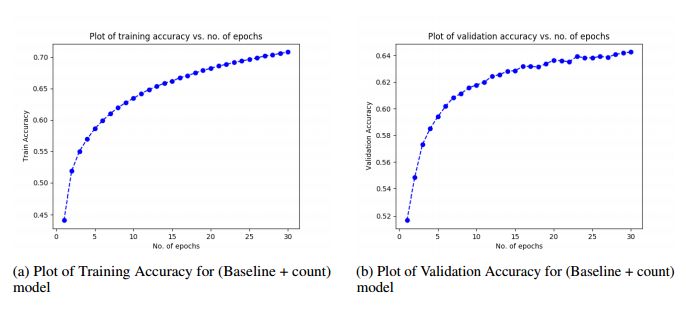
6.Reproducibility Report for "Learning To Count Objects In Natural Images For Visual Question Answering"(“学习计数自然图像中的物体来回答视觉问题”的再现性报告)
作者:Shagun Sodhani,Vardaan Pahuja
Submitted to Reproducibility in ML Workshop, ICML'18
机构:Université de Montréal
摘要:This is the reproducibility report for the paper "Learning To Count Objects In Natural Images For Visual QuestionAnswering"
期刊:arXiv, 2018年5月22日
网址:
http://www.zhuanzhi.ai/document/417b06cf1b274e183cada003d5eb6106
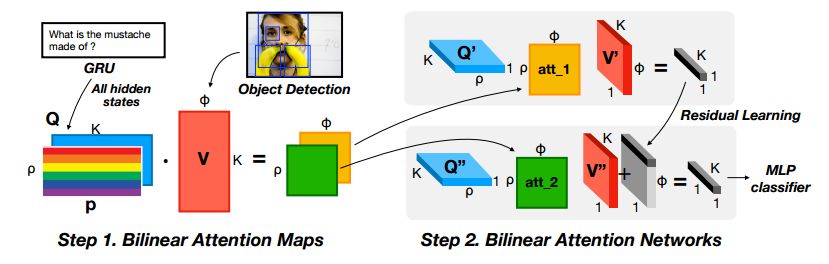
7.Bilinear Attention Networks(双线性注意力网络)
作者:Jin-Hwa Kim,Jaehyun Jun,Byoung-Tak Zhang
机构:Seoul National University
摘要:Attention networks in multimodal learning provide an efficient way to utilize given visual information selectively. However, the computational cost to learn attention distributions for every pair of multimodal input channels is prohibitively expensive. To solve this problem, co-attention builds two separate attention distributions for each modality neglecting the interaction between multimodal inputs. In this paper, we propose bilinear attention networks (BAN) that find bilinear attention distributions to utilize given vision-language information seamlessly. BAN considers bilinear interactions among two groups of input channels, while low-rank bilinear pooling extracts the joint representations for each pair of channels. Furthermore, we propose a variant of multimodal residual networks to exploit eight-attention maps of the BAN efficiently. We quantitatively and qualitatively evaluate our model on visual question answering (VQA 2.0) and Flickr30k Entities datasets, showing that BAN significantly outperforms previous methods and achieves new state-of-the-arts on both datasets.
期刊:arXiv, 2018年5月21日
网址:
http://www.zhuanzhi.ai/document/560e6c0a688cc444322ca80a7b675189
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知



