摘要——扩散语言模型(Diffusion Language Models,DLMs)正迅速崛起,成为主流自回归(autoregressive, AR)范式的一种强大且极具潜力的替代方案。通过在迭代去噪过程中并行生成 token,DLMs 在降低推理延迟和捕获双向上下文方面具有天然优势,从而能够对生成过程进行细粒度控制。在实现数倍推理加速的同时,近期的研究进展已使 DLMs 的性能可与自回归模型相媲美,使其在多种自然语言处理任务中成为具有吸引力的选择。尽管 DLMs 的应用日益普及,但其仍存在需要进一步探索的挑战与机遇,这需要对其原理、技术与局限性进行系统且深入的理解。在本综述中,我们对当前 DLM 领域进行了整体性梳理。我们追溯了其演化历程以及与其他范式(如自回归模型和掩码语言模型)的关系,涵盖了基础原理与最新前沿模型。本研究还提供了最新、全面的分类体系,并深入分析了当前技术,从预训练策略到先进的后训练方法。另一项贡献是全面回顾了 DLM 的推理策略与优化方法,包括解码并行化、缓存机制以及生成质量提升等方面的改进。我们还重点介绍了 DLM 在多模态扩展上的最新方法,并阐述了其在多种实际场景中的应用。此外,我们讨论了 DLM 的局限与挑战,包括效率、长序列处理以及基础设施需求,并展望了支撑该快速发展领域持续进步的未来研究方向。项目 GitHub 地址:https://github.com/VILA-Lab/Awesome-DLMs。
关键词——扩散语言模型,大语言模型,扩散模型,扩散式大语言模型,语言建模,多模态语言模型
1 引言
近期在通用人工智能(AGI)方面的进展,主要得益于自回归大型语言模型(autoregressive large language models,LLMs)[1]–[7] 的出现,以及面向图像与视频生成的扩散模型(diffusion models)[8]–[12] 的兴起。这些模型在跨多种模态的理解与生成任务中展现出了非凡能力,达到了过去难以想象的性能水平。它们在参数规模、数据集体量、训练投入以及推理阶段的计算开销等方面的前所未有的规模,推动了人工智能达到新的高度,使得这些模型具备广泛的通用知识以及对语言与真实世界的深刻理解。 GPT 系列 [1], [13], [14] 的崛起,尤其是 ChatGPT [2] 的公开发布,使得自回归(AR)语言模型在自然语言处理领域占据了主导地位。AR 模型通过因果注意力(causal attention)与教师强制(teacher forcing)来预测下一个 token [4], [15], [16],能够高效扩展至大规模数据集和模型规模。在推理时,AR 模型以逐 token 顺序生成文本,在支持从简单问答到复杂推理与创意写作的广泛任务中表现出色。然而,这种顺序生成的特性在推理速度上形成了主要瓶颈——AR 模型一次仅能生成一个 token,天生缺乏并行性,从而显著限制了计算效率与吞吐量。
扩散模型则是另一种极具潜力的生成范式。它们通过迭代去噪(denoising)过程,从逐步加噪的数据中恢复原始数据,并在生成阶段以相反顺序逆转这一随机扰动过程。在复杂数据分布建模方面,扩散模型已在图像与视频合成中实现了最新的性能记录 [17]。扩散建模的学术突破 [18]–[21] 为训练与推理奠定了坚实的理论基础;同时,大规模实用模型如 Stable Diffusion [8], [10], [11]、Imagen [9] 与 Sora [12] 展现了扩散范式在可扩展性与泛化能力上的非凡表现——只需几行文本提示,即可生成高保真、艺术级别的图像与视频。除对复杂数据分布的强大建模能力外,扩散模型还具有并行性的天然优势:通过迭代去噪,它们可以一次性生成多个 token,甚至整个序列,从而在推理吞吐与现代并行计算硬件利用率上具备潜在优势。尽管在建模离散数据和处理动态序列长度方面仍存在挑战,扩散语言模型(Diffusion Language Models, DLMs)已逐渐成为在生成质量与速度权衡上颇具吸引力的替代方案。
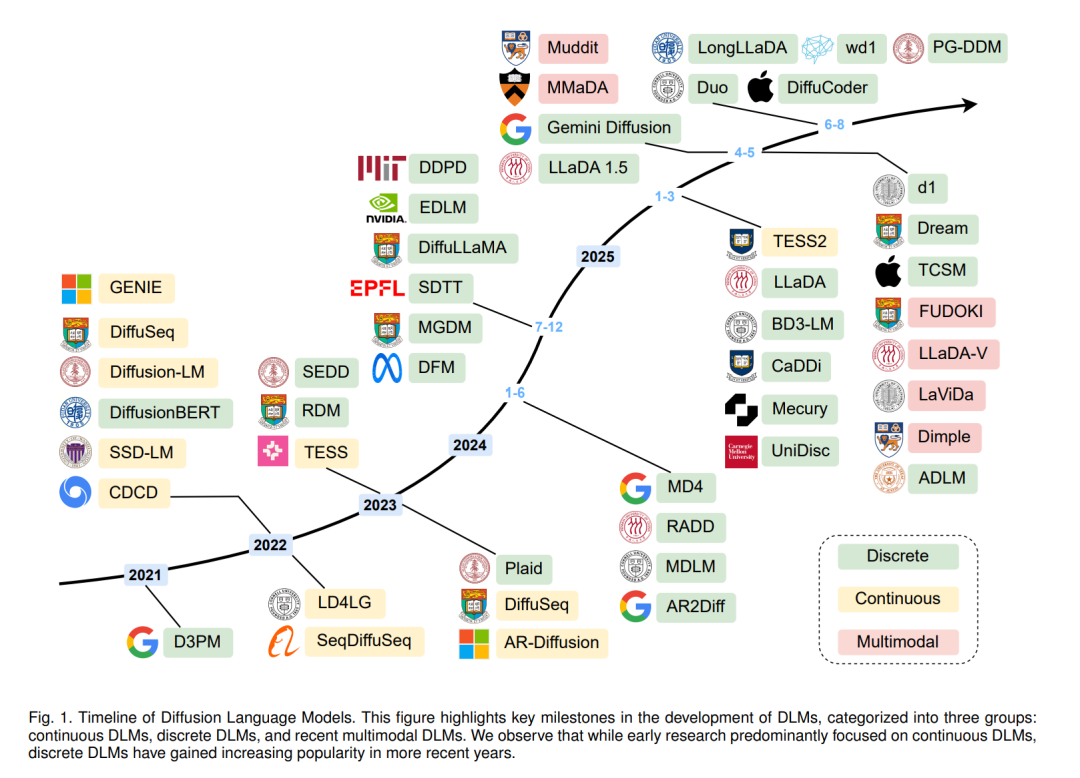
为了将扩散方法适配于离散语言数据,已有多种关键方法被提出。早期 DLMs 的发展主要受益于扩散模型在连续域(如图像生成)的成功。连续型 DLMs 会将 token 映射到嵌入向量,在连续空间中进行去噪,如 Diffusion-LM [22] 与 SED [23]。离散型 DLMs 则直接在 token 空间定义扩散过程,早期方法如 D3PM [24] 引入了带有吸收态(absorbing states)的结构化转移矩阵,实现了 token 级的扰动与迭代去噪;后续工作如 DiffusionBERT [25] 则结合了预训练掩码语言模型(如 BERT)以提升去噪质量,并提出了定制化的噪声调度策略(如 spindle schedule)以更好地匹配 token 扰动与词频分布。这些早期模型证明了将迭代去噪应用于非自回归文本生成的可行性,并带来了可控性与并行性,但其性能仍落后于强大的自回归基线。随着 DLMs 核心挑战的逐步解决与范式的成熟,更大规模的 DLMs 得以构建。例如,通过从自回归模型初始化,Dream [26] 与 DiffuLLaMA [27] 等 70 亿参数级模型证明了 DLMs 可在利用已有模型的同时实现具竞争力的性能;LLaDA-8B [28] 更进一步展示了从零训练 DLMs 的潜力,其性能可与同规模的 LLaMA3-8B 相媲美。多模态 DLMs(又称扩散多模态大语言模型,dMLLMs)也展现了在混合数据(如文本与图像)建模上的前景,基于开源 DLMs 的 LLaDA-V [29]、Dimple [30] 与 MMaDA [31] 等模型,将跨模态推理与生成融入扩散框架中。同时,业界也开始展现出对 DLMs 的浓厚兴趣,如 Mercury 系列 [32] 与 Gemini Diffusion [33] 在报告中不仅取得了出色性能,还实现了每秒生成数千 token 的推理速度。这些进展凸显了 DLMs 日益增长的实用性与商业潜力。
DLMs 在训练与推理阶段也呈现出独特的挑战与机遇。预训练通常借鉴自回归语言模型或图像扩散模型的策略 [26], [30], [31];为加快训练并复用已有成果,许多 DLMs 直接从预训练的自回归模型权重初始化 [26], [27]。在监督微调(SFT)阶段,DLMs 与 AR 模型类似,通过干净的提示数据学习生成目标补全。强化学习(RL)也被用于 DLMs 的后训练阶段,以提升复杂任务性能;在 GRPO [41] 算法基础上,diffu-GRPO [42] 与 UniGRPO [31] 等变体被提出,以增强大规模 DLMs 的推理能力与对齐效果。在推理阶段,连续型 DLMs 可利用 ODE/SDE 求解器或少步生成技术来加速迭代去噪过程 [43];针对离散型 DLMs 在并行生成方面的更多挑战,已有专门的并行解码策略 [30], [44], [45],以在单步中接受多个 token,克服并行瓶颈;解掩码与再掩码(unmasking/remasking)策略 [28], [46] 则通过有选择地揭示低置信度 token 来提升生成质量;而缓存技术 [47], [48] 则可显著减少计算量并提升推理速度,这对两类 DLMs 都适用。 相较于自回归模型,扩散语言模型普遍被认为具有以下优势: * 并行生成:DLMs 可通过迭代去噪过程并行生成多个 token,大幅提升推理速度与吞吐量。 * 双向上下文:DLMs 自然融合双向上下文,能够进行更细腻的语言理解与生成,并产生更丰富的上下文嵌入,这对于跨模态生成任务尤为有益,也支持对生成过程的精细化控制。 * 迭代精炼:迭代去噪过程允许 DLMs 在多个步骤中不断更新生成结果。通过提前接受高置信度 token、保留低置信度区域为掩码,掩码式 DLMs 可逐步改进不确定部分,从而生成更连贯、更高质量的文本。 * 可控性:DLMs 可在特定 token 位置或结构上进行条件生成,适用于填空(infilling)和结构化生成等任务;此外,分类器自由引导(classifier-free guidance)等技术还能更好地控制生成风格与语义相关性。 * 跨模态统一建模:基于统一的去噪建模框架,DLMs 天然支持文本与视觉的联合生成任务,这使其在需要生成与理解能力一体化的多模态应用中具有独特潜力。
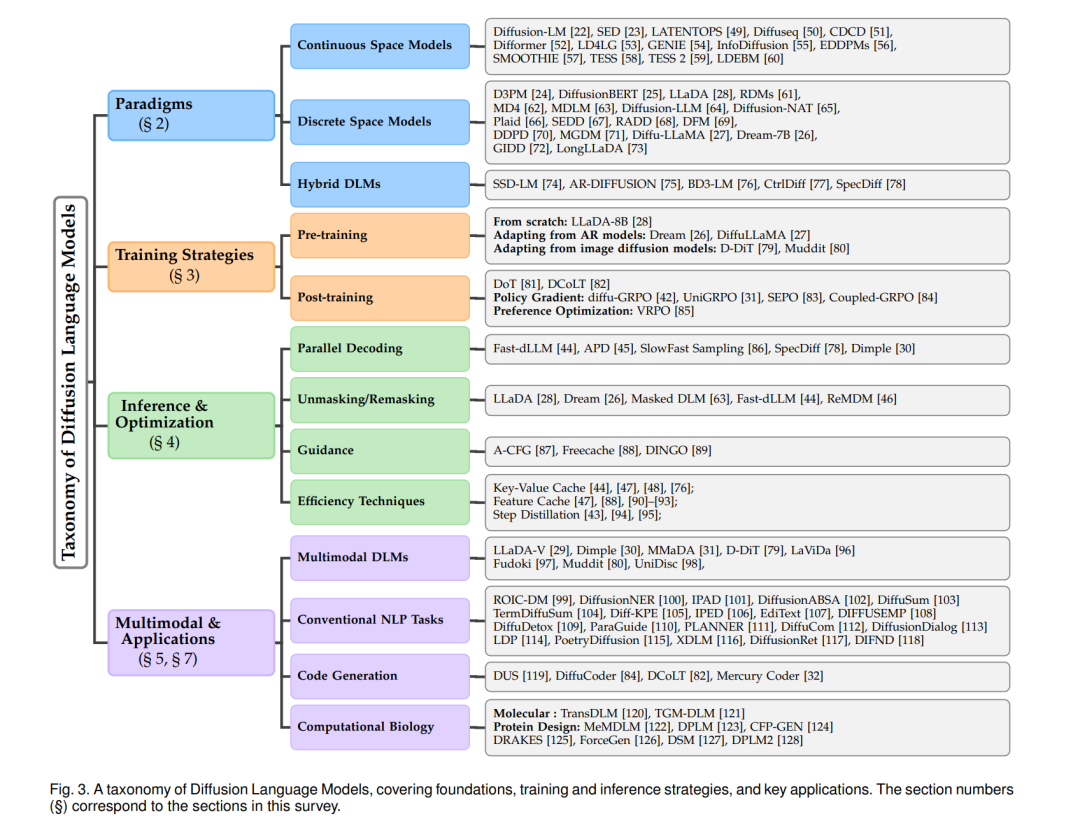
尽管近年来 DLMs 热度迅速攀升,但尚缺乏一篇系统覆盖整个 DLM 生态的全面综述。我们在本综述的结构安排如下:第 2 节对现代语言建模范式进行全面回顾,包括自回归、掩码式与基于扩散的方法;第 3 节深入探讨 DLMs 的训练方法,包括预训练、监督微调(SFT)与强化学习(RL)对齐等技术;第 4 节介绍多种推理策略与优化方法,重点关注适用于连续与离散空间模型的技术;第 5 节探讨扩散模型在多模态场景下的拓展,综述 LLaDA-V [29]、MMaDA [31]、Dimple [30] 等前沿架构;第 6 节呈现并可视化 DLMs 的性能对比;第 7 节展示 DLMs 在文本生成、代码生成、计算生物学等多种任务中的应用;第 8 节则讨论 DLMs 面临的挑战与局限,包括效率、推理能力、智能体能力及基础设施等问题,并展望未来的研究方向。为提供整体性概览,我们在图 3 中给出了 DLMs 的分类体系。
1 引言
近期在通用人工智能(AGI)方面的进展,主要得益于自回归大型语言模型(autoregressive large language models,LLMs)[1]–[7] 的出现,以及面向图像与视频生成的扩散模型(diffusion models)[8]–[12] 的兴起。这些模型在跨多种模态的理解与生成任务中展现出了非凡能力,达到了过去难以想象的性能水平。它们在参数规模、数据集体量、训练投入以及推理阶段的计算开销等方面的前所未有的规模,推动了人工智能达到新的高度,使得这些模型具备广泛的通用知识以及对语言与真实世界的深刻理解。 GPT 系列 [1], [13], [14] 的崛起,尤其是 ChatGPT [2] 的公开发布,使得自回归(AR)语言模型在自然语言处理领域占据了主导地位。AR 模型通过因果注意力(causal attention)与教师强制(teacher forcing)来预测下一个 token [4], [15], [16],能够高效扩展至大规模数据集和模型规模。在推理时,AR 模型以逐 token 顺序生成文本,在支持从简单问答到复杂推理与创意写作的广泛任务中表现出色。然而,这种顺序生成的特性在推理速度上形成了主要瓶颈——AR 模型一次仅能生成一个 token,天生缺乏并行性,从而显著限制了计算效率与吞吐量。 扩散模型则是另一种极具潜力的生成范式。它们通过迭代去噪(denoising)过程,从逐步加噪的数据中恢复原始数据,并在生成阶段以相反顺序逆转这一随机扰动过程。在复杂数据分布建模方面,扩散模型已在图像与视频合成中实现了最新的性能记录 [17]。扩散建模的学术突破 [18]–[21] 为训练与推理奠定了坚实的理论基础;同时,大规模实用模型如 Stable Diffusion [8], [10], [11]、Imagen [9] 与 Sora [12] 展现了扩散范式在可扩展性与泛化能力上的非凡表现——只需几行文本提示,即可生成高保真、艺术级别的图像与视频。除对复杂数据分布的强大建模能力外,扩散模型还具有并行性的天然优势:通过迭代去噪,它们可以一次性生成多个 token,甚至整个序列,从而在推理吞吐与现代并行计算硬件利用率上具备潜在优势。尽管在建模离散数据和处理动态序列长度方面仍存在挑战,扩散语言模型(Diffusion Language Models, DLMs)已逐渐成为在生成质量与速度权衡上颇具吸引力的替代方案。 为了将扩散方法适配于离散语言数据,已有多种关键方法被提出。早期 DLMs 的发展主要受益于扩散模型在连续域(如图像生成)的成功。连续型 DLMs 会将 token 映射到嵌入向量,在连续空间中进行去噪,如 Diffusion-LM [22] 与 SED [23]。离散型 DLMs 则直接在 token 空间定义扩散过程,早期方法如 D3PM [24] 引入了带有吸收态(absorbing states)的结构化转移矩阵,实现了 token 级的扰动与迭代去噪;后续工作如 DiffusionBERT [25] 则结合了预训练掩码语言模型(如 BERT)以提升去噪质量,并提出了定制化的噪声调度策略(如 spindle schedule)以更好地匹配 token 扰动与词频分布。这些早期模型证明了将迭代去噪应用于非自回归文本生成的可行性,并带来了可控性与并行性,但其性能仍落后于强大的自回归基线。随着 DLMs 核心挑战的逐步解决与范式的成熟,更大规模的 DLMs 得以构建。例如,通过从自回归模型初始化,Dream [26] 与 DiffuLLaMA [27] 等 70 亿参数级模型证明了 DLMs 可在利用已有模型的同时实现具竞争力的性能;LLaDA-8B [28] 更进一步展示了从零训练 DLMs 的潜力,其性能可与同规模的 LLaMA3-8B 相媲美。多模态 DLMs(又称扩散多模态大语言模型,dMLLMs)也展现了在混合数据(如文本与图像)建模上的前景,基于开源 DLMs 的 LLaDA-V [29]、Dimple [30] 与 MMaDA [31] 等模型,将跨模态推理与生成融入扩散框架中。同时,业界也开始展现出对 DLMs 的浓厚兴趣,如 Mercury 系列 [32] 与 Gemini Diffusion [33] 在报告中不仅取得了出色性能,还实现了每秒生成数千 token 的推理速度。这些进展凸显了 DLMs 日益增长的实用性与商业潜力。

DLMs 在训练与推理阶段也呈现出独特的挑战与机遇。预训练通常借鉴自回归语言模型或图像扩散模型的策略 [26], [30], [31];为加快训练并复用已有成果,许多 DLMs 直接从预训练的自回归模型权重初始化 [26], [27]。在监督微调(SFT)阶段,DLMs 与 AR 模型类似,通过干净的提示数据学习生成目标补全。强化学习(RL)也被用于 DLMs 的后训练阶段,以提升复杂任务性能;在 GRPO [41] 算法基础上,diffu-GRPO [42] 与 UniGRPO [31] 等变体被提出,以增强大规模 DLMs 的推理能力与对齐效果。在推理阶段,连续型 DLMs 可利用 ODE/SDE 求解器或少步生成技术来加速迭代去噪过程 [43];针对离散型 DLMs 在并行生成方面的更多挑战,已有专门的并行解码策略 [30], [44], [45],以在单步中接受多个 token,克服并行瓶颈;解掩码与再掩码(unmasking/remasking)策略 [28], [46] 则通过有选择地揭示低置信度 token 来提升生成质量;而缓存技术 [47], [48] 则可显著减少计算量并提升推理速度,这对两类 DLMs 都适用。 相较于自回归模型,扩散语言模型普遍被认为具有以下优势: * 并行生成:DLMs 可通过迭代去噪过程并行生成多个 token,大幅提升推理速度与吞吐量。 * 双向上下文:DLMs 自然融合双向上下文,能够进行更细腻的语言理解与生成,并产生更丰富的上下文嵌入,这对于跨模态生成任务尤为有益,也支持对生成过程的精细化控制。 * 迭代精炼:迭代去噪过程允许 DLMs 在多个步骤中不断更新生成结果。通过提前接受高置信度 token、保留低置信度区域为掩码,掩码式 DLMs 可逐步改进不确定部分,从而生成更连贯、更高质量的文本。 * 可控性:DLMs 可在特定 token 位置或结构上进行条件生成,适用于填空(infilling)和结构化生成等任务;此外,分类器自由引导(classifier-free guidance)等技术还能更好地控制生成风格与语义相关性。 * 跨模态统一建模:基于统一的去噪建模框架,DLMs 天然支持文本与视觉的联合生成任务,这使其在需要生成与理解能力一体化的多模态应用中具有独特潜力。
尽管近年来 DLMs 热度迅速攀升,但尚缺乏一篇系统覆盖整个 DLM 生态的全面综述。我们在本综述的结构安排如下:第 2 节对现代语言建模范式进行全面回顾,包括自回归、掩码式与基于扩散的方法;第 3 节深入探讨 DLMs 的训练方法,包括预训练、监督微调(SFT)与强化学习(RL)对齐等技术;第 4 节介绍多种推理策略与优化方法,重点关注适用于连续与离散空间模型的技术;第 5 节探讨扩散模型在多模态场景下的拓展,综述 LLaDA-V [29]、MMaDA [31]、Dimple [30] 等前沿架构;第 6 节呈现并可视化 DLMs 的性能对比;第 7 节展示 DLMs 在文本生成、代码生成、计算生物学等多种任务中的应用;第 8 节则讨论 DLMs 面临的挑战与局限,包括效率、推理能力、智能体能力及基础设施等问题,并展望未来的研究方向。为提供整体性概览,我们在图 3 中给出了 DLMs 的分类体系。