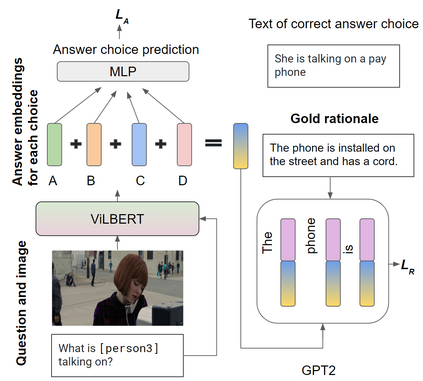
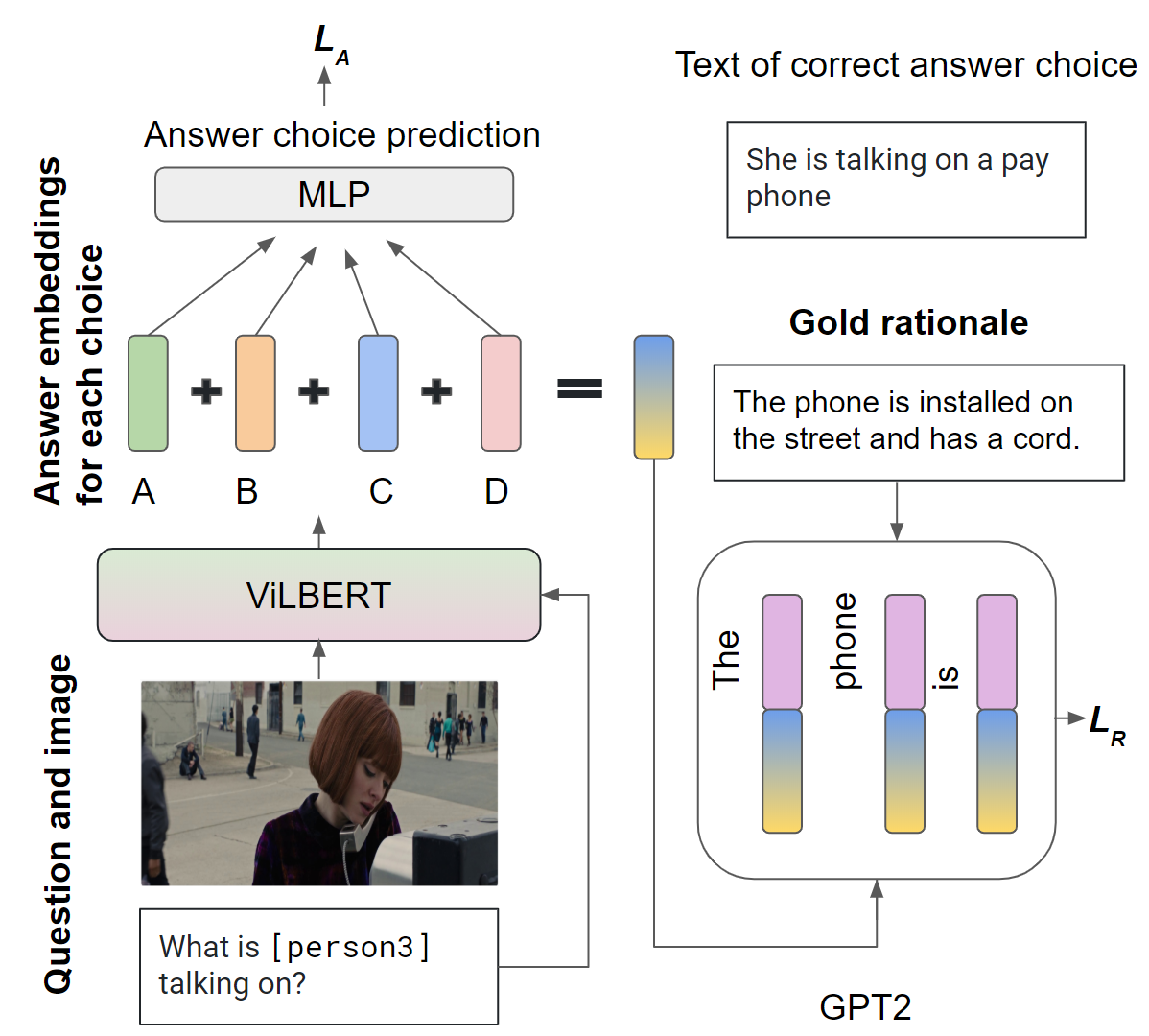
Despite recent advances in Visual QuestionAnswering (VQA), it remains a challenge todetermine how much success can be attributedto sound reasoning and comprehension ability.We seek to investigate this question by propos-ing a new task ofrationale generation. Es-sentially, we task a VQA model with generat-ing rationales for the answers it predicts. Weuse data from the Visual Commonsense Rea-soning (VCR) task, as it contains ground-truthrationales along with visual questions and an-swers. We first investigate commonsense un-derstanding in one of the leading VCR mod-els, ViLBERT, by generating rationales frompretrained weights using a state-of-the-art lan-guage model, GPT-2. Next, we seek to jointlytrain ViLBERT with GPT-2 in an end-to-endfashion with the dual task of predicting the an-swer in VQA and generating rationales. Weshow that this kind of training injects com-monsense understanding in the VQA modelthrough quantitative and qualitative evaluationmetrics
翻译:尽管在视觉问答(VQA)方面最近有所进展,但确定有多少成功可以归功于合理的推理和理解能力仍然是一项挑战。 我们试图通过提出一个新的逻辑一代任务来调查这一问题。 从表面看,我们使用一个具有基因学原理的VQA模型来预测答案。 我们使用视觉常识Resoning(VCR)任务中的数据,因为它包含地面曲线,连同视觉问题和投影。我们首先通过利用最新的断层模型(GPT-2)来从预选重量中产生理由,对VCRM-els(VLBERT)中常见的不发育状态进行调查。接下来,我们寻求将VLBERT-2(VPT-2)与GPT-2(VPT-2)联合起来,其双重任务是预测VQA中的一台天文台,并产生理由。我们展示了这种在VQA中进行定量和定性评估的培训模型。