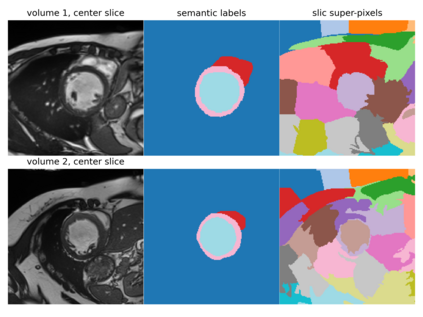
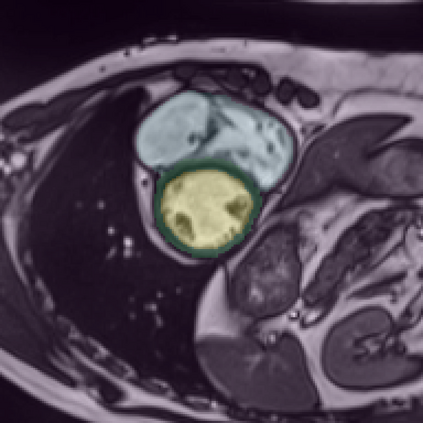
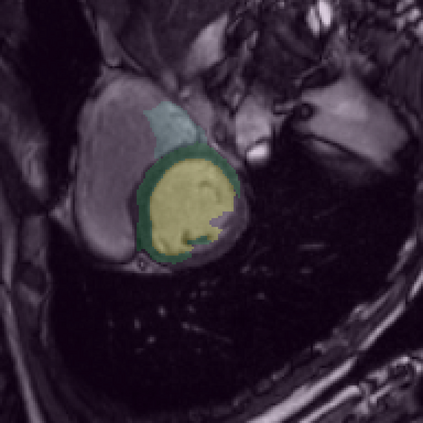
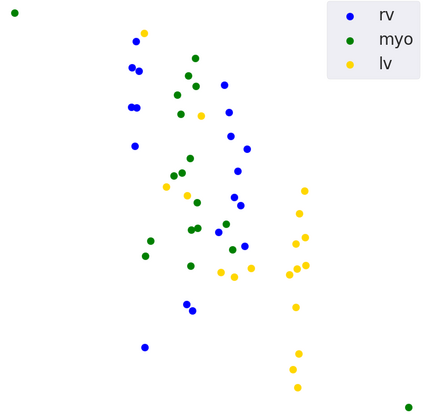
Supervised deep learning-based methods yield accurate results for medical image segmentation. However, they require large labeled datasets for this, and obtaining them is a laborious task that requires clinical expertise. Semi/self-supervised learning-based approaches address this limitation by exploiting unlabeled data along with limited annotated data. Recent self-supervised learning methods use contrastive loss to learn good global level representations from unlabeled images and achieve high performance in classification tasks on popular natural image datasets like ImageNet. In pixel-level prediction tasks such as segmentation, it is crucial to also learn good local level representations along with global representations to achieve better accuracy. However, the impact of the existing local contrastive loss-based methods remains limited for learning good local representations because similar and dissimilar local regions are defined based on random augmentations and spatial proximity; not based on the semantic label of local regions due to lack of large-scale expert annotations in the semi/self-supervised setting. In this paper, we propose a local contrastive loss to learn good pixel level features useful for segmentation by exploiting semantic label information obtained from pseudo-labels of unlabeled images alongside limited annotated images. In particular, we define the proposed loss to encourage similar representations for the pixels that have the same pseudo-label/ label while being dissimilar to the representation of pixels with different pseudo-label/label in the dataset. We perform pseudo-label based self-training and train the network by jointly optimizing the proposed contrastive loss on both labeled and unlabeled sets and segmentation loss on only the limited labeled set. We evaluated on three public cardiac and prostate datasets, and obtain high segmentation performance.
翻译:受监督的深层学习方法为医学图像分割带来准确的结果。 但是,它们要求为此提供大量标签化数据集。 获取这些数据集是需要临床专门知识的艰巨任务。 半/自监督的学习方法通过利用无标签化数据以及有限的附加说明数据来应对这一局限性。 最近自我监督的学习方法使用对比性损失来从未贴标签的图像中学习良好的全球层面的表示方式,并在像图像网这样的广受欢迎的自然图像数据集的分类任务中取得高性能。 在像素级的预测任务中,例如分解,还必须学习良好的当地一级的表示方式以及全球表示方式来提高准确性。 然而,现有的本地对比性损失法对于学习良好的当地表示方式的影响仍然有限,因为相似和不同的地方区域的定义是基于随机放大和空间接近的;不是基于本地区域的语义标签标签标签标签,因为在半/自我监控的设置中缺少大规模专家说明。 在本文中,我们建议对本地的显示损失进行比较性损失是为了学习好的非像素级的表示方式,通过利用纸质化的标签化的表示, 与我们提出的贴标签上的显示为不同的表示,我们所获取的贴标签的标签上的标签上的显示的标签上的表示。