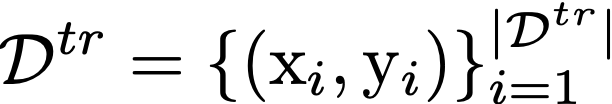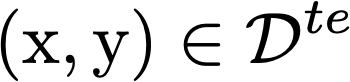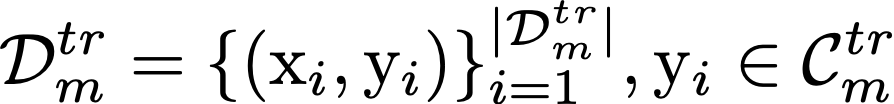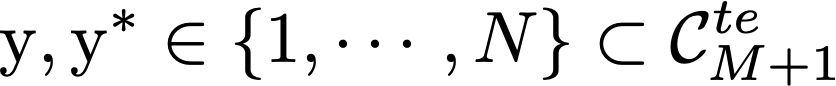Model agnostic meta-learning algorithms aim to infer priors from several observed tasks that can then be used to adapt to a new task with few examples. Given the inherent diversity of tasks arising in existing benchmarks, recent methods use separate, learnable structure, such as hierarchies or graphs, for enabling task-specific adaptation of the prior. While these approaches have produced significantly better meta learners, our goal is to improve their performance when the heterogeneous task distribution contains challenging distribution shifts and semantic disparities. To this end, we introduce CAML (Contrastive Knowledge-Augmented Meta Learning), a novel approach for knowledge-enhanced few-shot learning that evolves a knowledge graph to effectively encode historical experience, and employs a contrastive distillation strategy to leverage the encoded knowledge for task-aware modulation of the base learner. Using standard benchmarks, we evaluate the performance of CAML in different few-shot learning scenarios. In addition to the standard few-shot task adaptation, we also consider the more challenging multi-domain task adaptation and few-shot dataset generalization settings in our empirical studies. Our results shows that CAML consistently outperforms best known approaches and achieves improved generalization.
翻译:由于现有基准所产生任务的内在多样性,最近的方法使用不同的、可学习的结构,例如等级或图表,以便根据具体任务对以前的任务进行调整。虽然这些方法产生了显著更好的元学习者,但我们的目标是,当不同的任务分配包含具有挑战性的分配变化和语义差异时,改进他们的业绩。为此,我们引入了CAML(知识强化元数据学习),一种创新的知识强化方法,即发展一个知识图表,以有效记录历史经验,并采用对比性蒸馏战略,利用编码知识对基础学习者进行任务认知调整。我们使用标准基准,评估不同微小的学习情景中CAML的绩效。除了标准的微小任务调整外,我们还考虑更具有挑战性的多任务调整和微小的概括化数据设置。我们已知的CAML方法不断改进。