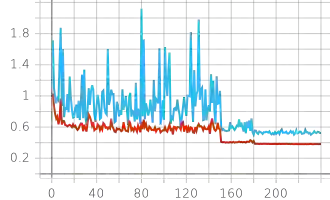
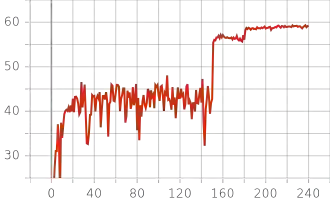
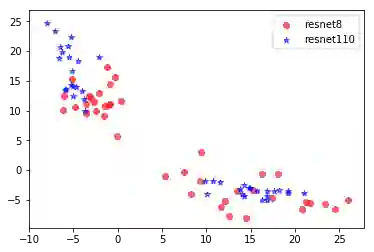
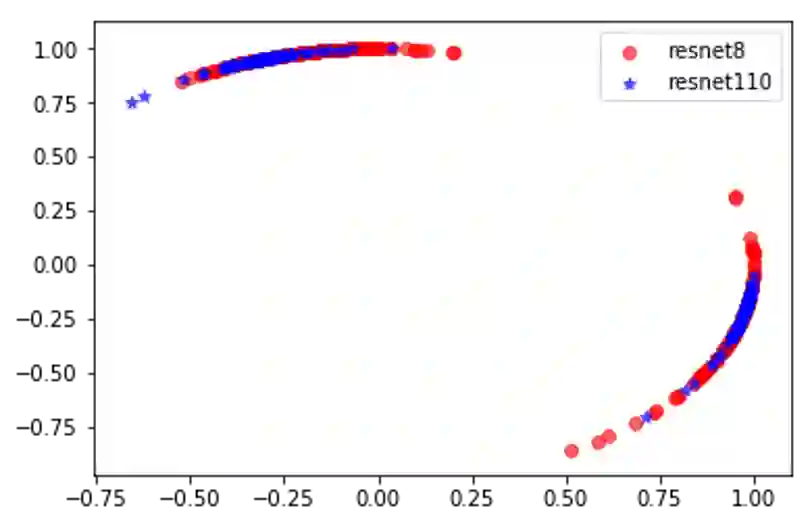
Knowledge distillation aims at obtaining a small but effective deep model by transferring knowledge from a much larger one. The previous approaches try to reach this goal by simply "logit-supervised" information transferring between the teacher and student, which somehow can be subsequently decomposed as the transfer of normalized logits and $l^2$ norm. We argue that the norm of logits is actually interference, which damages the efficiency in the transfer process. To address this problem, we propose Spherical Knowledge Distillation (SKD). Specifically, we project the teacher and the student's logits into a unit sphere, and then we can efficiently perform knowledge distillation on the sphere. We verify our argument via theoretical analysis and ablation study. Extensive experiments have demonstrated the superiority and scalability of our method over the SOTAs.
翻译:知识蒸馏的目的是通过从大得多的知识中传授知识来获得一个小型但有效的深层模型。 以往的方法试图通过在教师和学生之间进行“ 由劳工监督的” 信息传输来达到这个目的,这种信息传递后来可能随着正常的登录和1美元2美元的规范的传输而分解。 我们争论说,登入的规范实际上是干扰,这损害了转让过程的效率。 为了解决这个问题,我们提议了球体知识蒸馏(SKD ) 。 具体地说,我们将教师和学生的登录记录投射到一个单元领域,然后我们可以有效地在球体上进行知识蒸馏。 我们通过理论分析和消化研究来验证我们的论点。 广泛的实验表明,我们的方法优于SOTA。