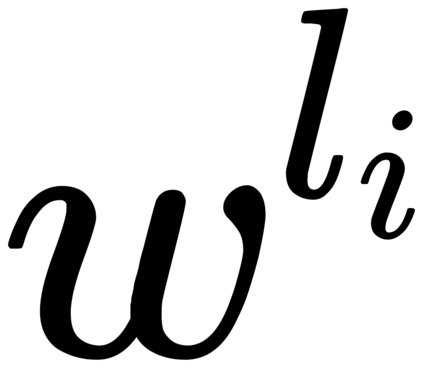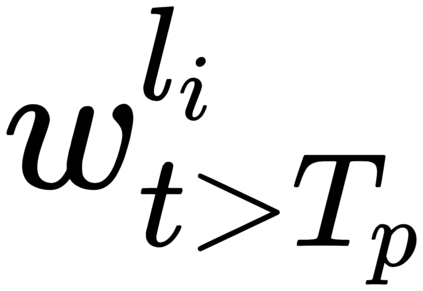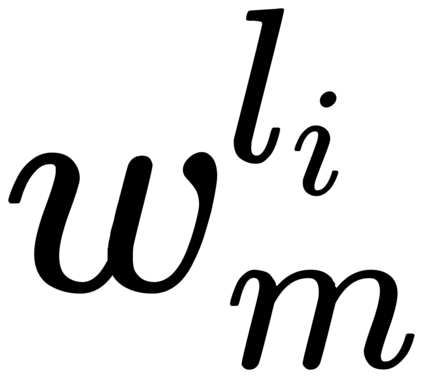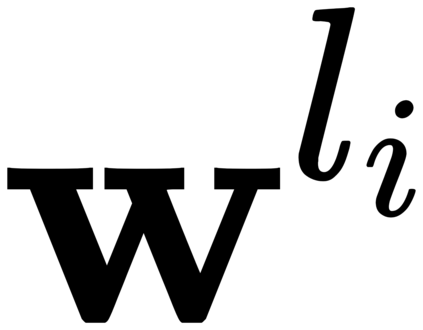Recent cross-lingual cross-modal works attempt to extend Vision-Language Pre-training (VLP) models to non-English inputs and achieve impressive performance. However, these models focus only on understanding tasks utilizing encoder-only architecture. In this paper, we propose ERNIE-UniX2, a unified cross-lingual cross-modal pre-training framework for both generation and understanding tasks. ERNIE-UniX2 integrates multiple pre-training paradigms (e.g., contrastive learning and language modeling) based on encoder-decoder architecture and attempts to learn a better joint representation across languages and modalities. Furthermore, ERNIE-UniX2 can be seamlessly fine-tuned for varieties of generation and understanding downstream tasks. Pre-trained on both multilingual text-only and image-text datasets, ERNIE-UniX2 achieves SOTA results on various cross-lingual cross-modal generation and understanding tasks such as multimodal machine translation and multilingual visual question answering.
翻译:最近的跨语言跨模式工作试图将愿景-语言培训前(VLP)模式扩大到非英语投入,并取得令人印象深刻的成绩;然而,这些模式仅侧重于利用只使用编码器的结构来理解任务;在本文件中,我们建议ERNIE-UniX2为产生和理解任务建立一个统一的跨语言跨模式培训前框架;ERNIE-UniX2结合了基于编码器-编码器结构的多种培训前模式(例如对比学习和语言建模),并试图学习不同语言和模式的更好的联合代表;此外,ERNIE-UniX2可以对新一代和理解下游任务进行无缝的调整;在多语言文本和图像-文字数据集方面预先培训,ERNIE-UniX2在多种语言跨模式的跨模式生成和理解任务上取得了SOTA结果,如多语言机器翻译和多语言视觉解答。