
主题: NEZHA: Neural Contextualized Representation for Chinese Language Understanding
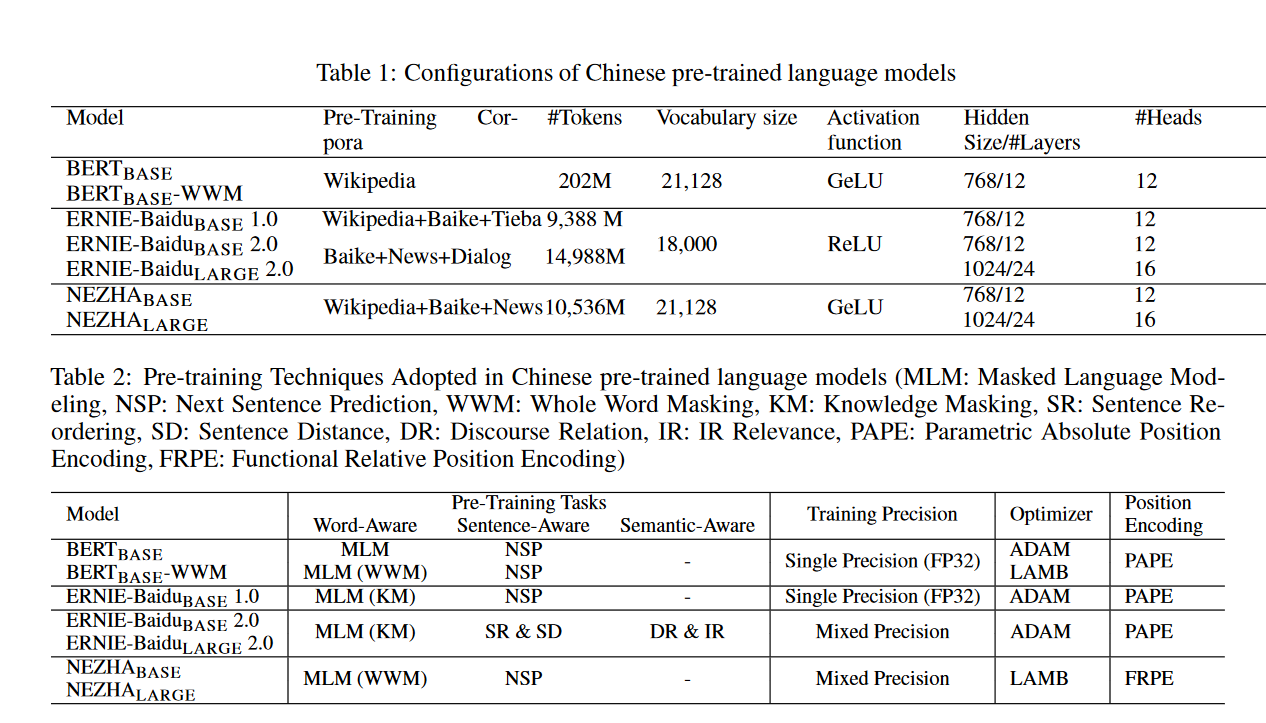
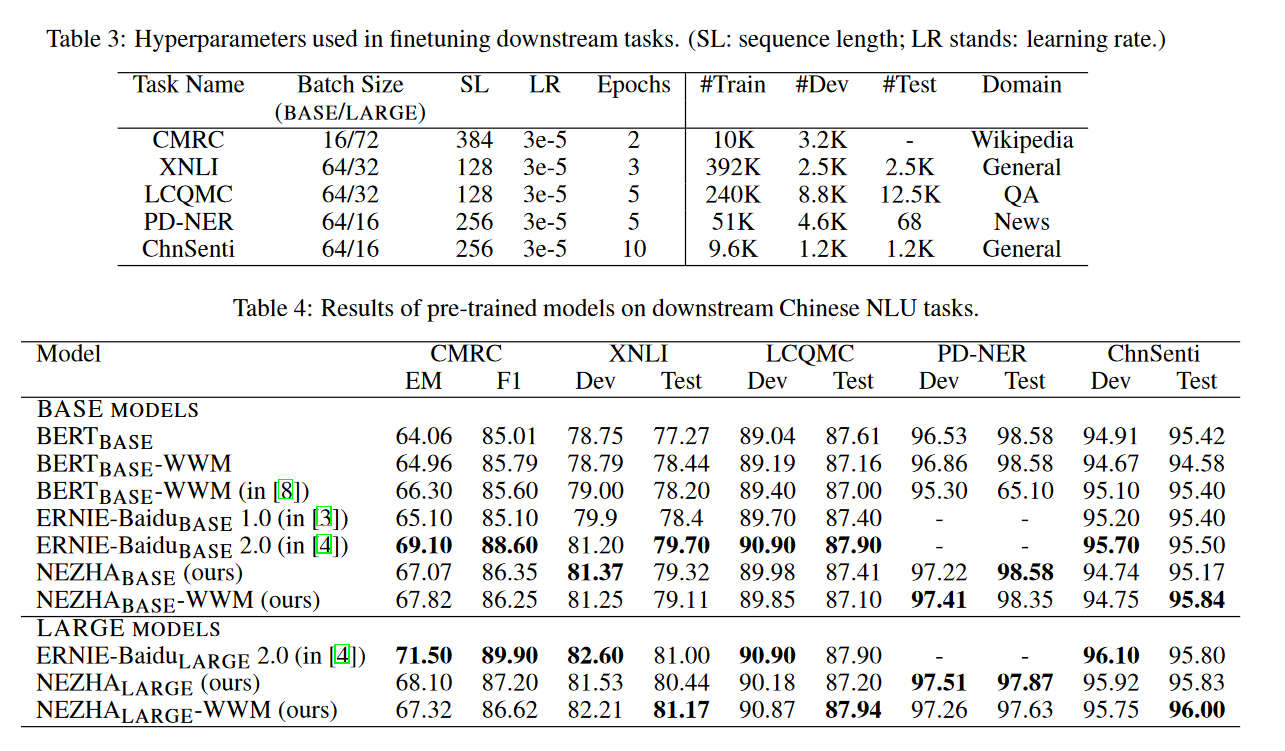
摘要: 预训练语言模型通过大规模语料库的预训练,能够捕捉文本中深层的语境信息,在各种自然语言理解任务中取得了巨大的成功。在本技术报告中,我们介绍了我们在中文语料库中使用的名为NEZHA(用于中文理解的神经上下文表示)的预训练语言模型,以及对中文NLU任务进行微调的实践。当前版本的NEZHA是基于BERT的,经过了大量的改进,包括作为一种有效的位置编码方案的功能相对位置编码、全字掩蔽策略、混合精度训练和LAMB优化器。实验结果表明,NEZHA在命名实体识别(People's Daily NER)、句子匹配(LCQMC)、汉语情感分类(ChnSenti)和自然语言推理(XNLI)等具有代表性的汉语任务上都取得了最新的性能。
作者简介: Xiaoguang Li,博士,深圳大学高级研究所助理教授。
Yasheng Wang,华为高级工程师。
成为VIP会员查看完整内容

相关内容

人工智能(Artificial Intelligence, AI )是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。 人工智能是计算机科学的一个分支。
专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
64+阅读 · 2020年4月28日
Arxiv
16+阅读 · 2019年5月24日




相关VIP内容
专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
64+阅读 · 2020年4月28日
相关资讯
相关论文
Arxiv
16+阅读 · 2019年5月24日