文字描述生成视频的开源项目
文字condition 视频
Attentive Semantic Video Generation using Captions
Tensorflow implementation for the paper Attentive Semantic Video Generation using Captions by Tanya Marwah*, Gaurav Mittal* and Vineeth N. Balasubramanian accepted at International Conference on Computer Vision 2017 (ICCV 2017) (*Equal Contribution).
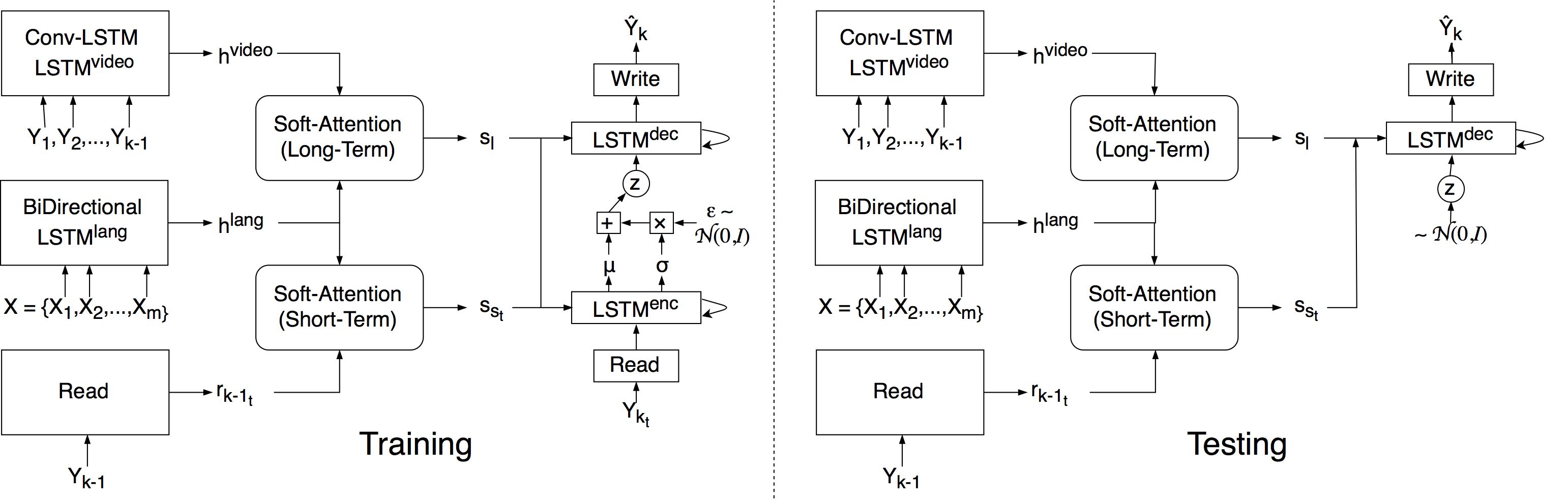
Proposed network architecture for attentive semantic video generation with captions.
Results
 |
 |
|---|---|
| digit 6 is moving up and down | digit 3 is moving left and right |
| person 4 is walking left to right |

Example of Spatio Temporal Style Transfer
 |
|---|
| Caption 1: digit 4 is moving up and down Caption 2: digit 4 is moving left and right |
 |
 |
|---|---|
| Caption 1: digit 4 is moving up and down Caption 2: digit 9 is moving left and right | Caption 1: digit 5 is moving left and right Caption 2: digit 9 is moving up and down |
| Caption 1: person 10 is walking left to right Caption 2: person 10 is walking right to left |

人物行走请阅读原文访问github看原图片
招聘公众号回复招聘
登录查看更多
相关内容

Arxiv
3+阅读 · 2018年11月20日
相关主题




相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年11月20日