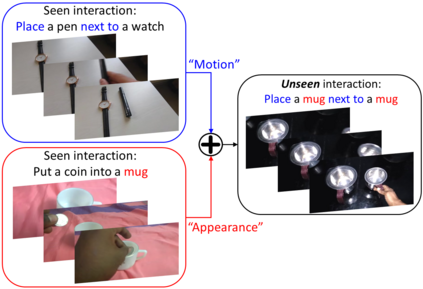
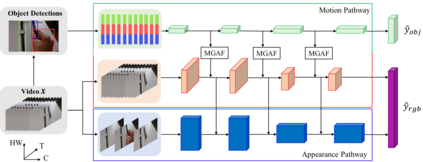
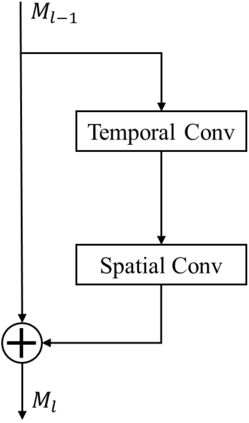
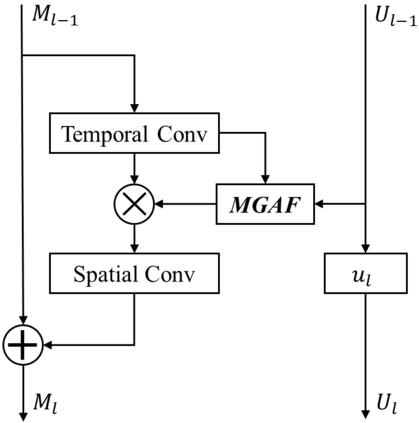
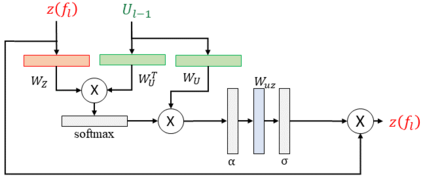
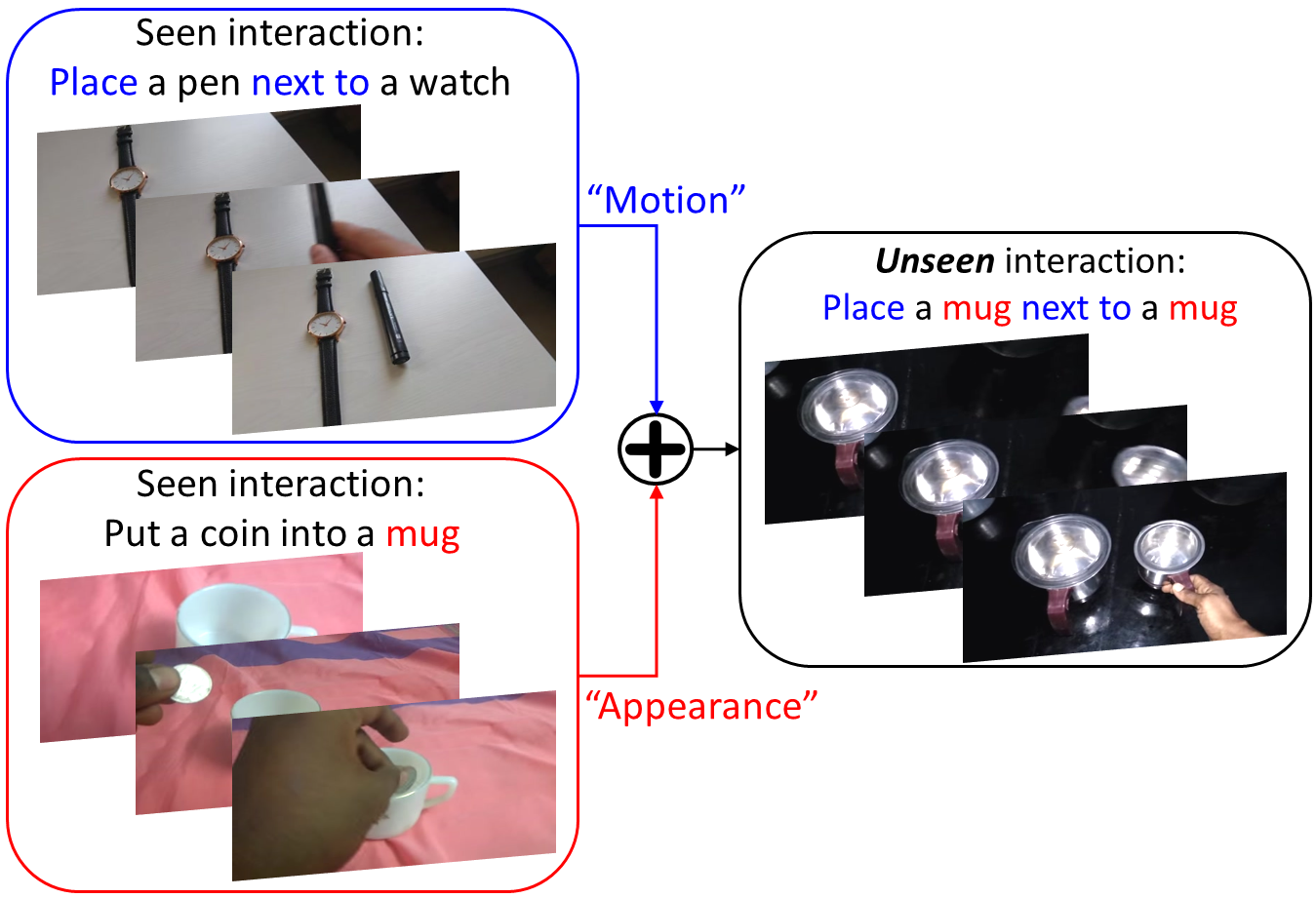
We present a dual-pathway approach for recognizing fine-grained interactions from videos. We build on the success of prior dual-stream approaches, but make a distinction between the static and dynamic representations of objects and their interactions explicit by introducing separate motion and object detection pathways. Then, using our new Motion-Guided Attention Fusion module, we fuse the bottom-up features in the motion pathway with features captured from object detections to learn the temporal aspects of an action. We show that our approach can generalize across appearance effectively and recognize actions where an actor interacts with previously unseen objects. We validate our approach using the compositional action recognition task from the Something-Something-v2 dataset where we outperform existing state-of-the-art methods. We also show that our method can generalize well to real world tasks by showing state-of-the-art performance on recognizing humans assembling various IKEA furniture on the IKEA-ASM dataset.
翻译:我们展示了一种双路径方法,以识别视频中细微的相互作用。 我们以先前的双流方法的成功为基础,但通过引入单独的运动和物体探测路径,区分物体静态和动态的表达方式及其显露的相互作用。 然后,我们利用我们新的运动-引导引力融合模块,将运动路径中自下而上的特点与从物体探测中采集的特征结合起来,以了解一项行动的时间方面。 我们表明,我们的方法可以有效地将外观加以概括,并承认一个行为者与以前看不见的物体发生相互作用时的行动。 我们用某些东西- 点数- V2 数据集的组合动作识别任务来验证我们的方法,在这些数据集中,我们优于现有的最新技术方法。 我们还表明,我们的方法可以通过在识别在IKEA- ASM数据集上组装各种IKEA家具的人时展示最先进的表现,从而将现实世界任务概括化。