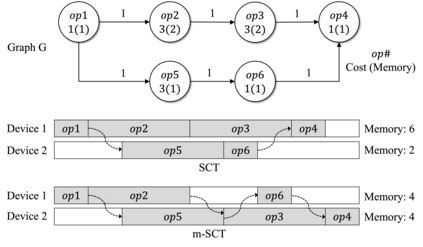
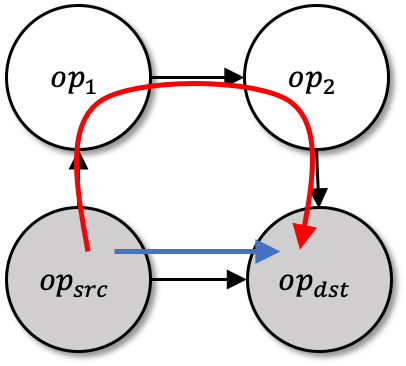
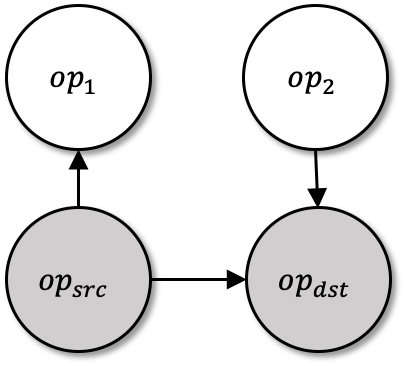
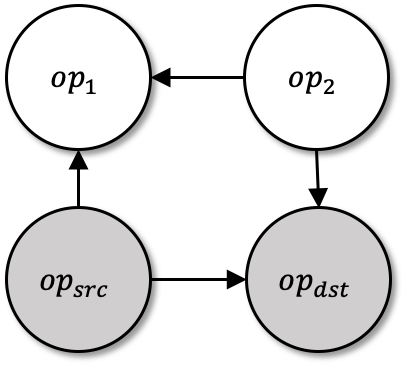
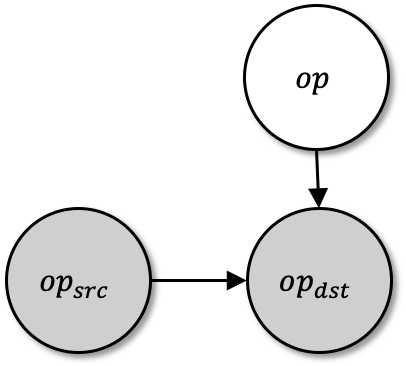
Machine Learning graphs (or models) can be challenging or impossible to train when either devices have limited memory, or models are large. To split the model across devices, learning-based approaches are still popular. While these result in model placements that train fast on data (i.e., low step times), learning-based model-parallelism is time-consuming, taking many hours or days to create a placement plan of operators on devices. We present the Baechi system, the first to adopt an algorithmic approach to the placement problem for running machine learning training graphs on small clusters of memory-constrained devices. We integrate our implementation of Baechi into two popular open-source learning frameworks: TensorFlow and PyTorch. Our experimental results using GPUs show that: (i) Baechi generates placement plans 654 X - 206K X faster than state-of-the-art learning-based approaches, and (ii) Baechi-placed model's step (training) time is comparable to expert placements in PyTorch, and only up to 6.2% worse than expert placements in TensorFlow. We prove mathematically that our two algorithms are within a constant factor of the optimal. Our work shows that compared to learning-based approaches, algorithmic approaches can face different challenges for adaptation to Machine learning systems, but also they offer proven bounds, and significant performance benefits.
翻译:当设备记忆有限或模型巨大时,机器学习图(或模型)可能具有挑战性或无法培训。为了将模型分成不同装置,学习方法仍然很受欢迎。虽然这些结果导致模型布置,快速培训数据(即低步数),但学习模型的平行主义模式耗费时间,需要许多小时或数日时间来创建装置操作员的安置计划。我们介绍Baechi系统,第一个在运行小型记忆限制装置集的机器学习培训图时,对安置问题采用算法方法。我们把Baechi的实施工作纳入两个受欢迎的开放源学习框架:TensorFlow和PyTorrch。我们使用GPUs的实验结果表明:(一) Baechi生成了654 X-206K X的布置计划,比目前最先进的学习方法更快,以及(二) Baechi-placed 模型的台阶(培训)时间与专家在PyTorch 中的位置安排相当,但仅达6.2%,比TensorFrch 的的专家布局更差。我们的最佳算算算算法方法可以显示我们最优的学习方法。