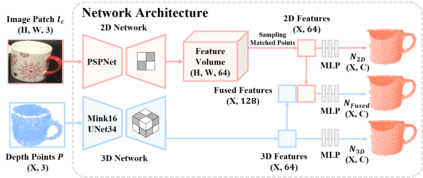
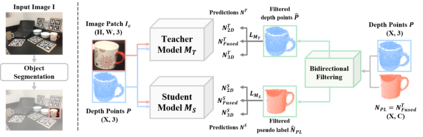
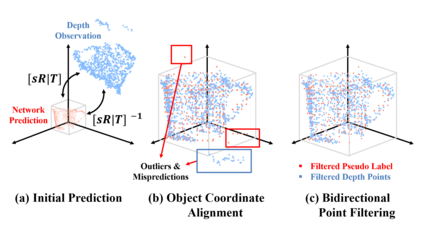
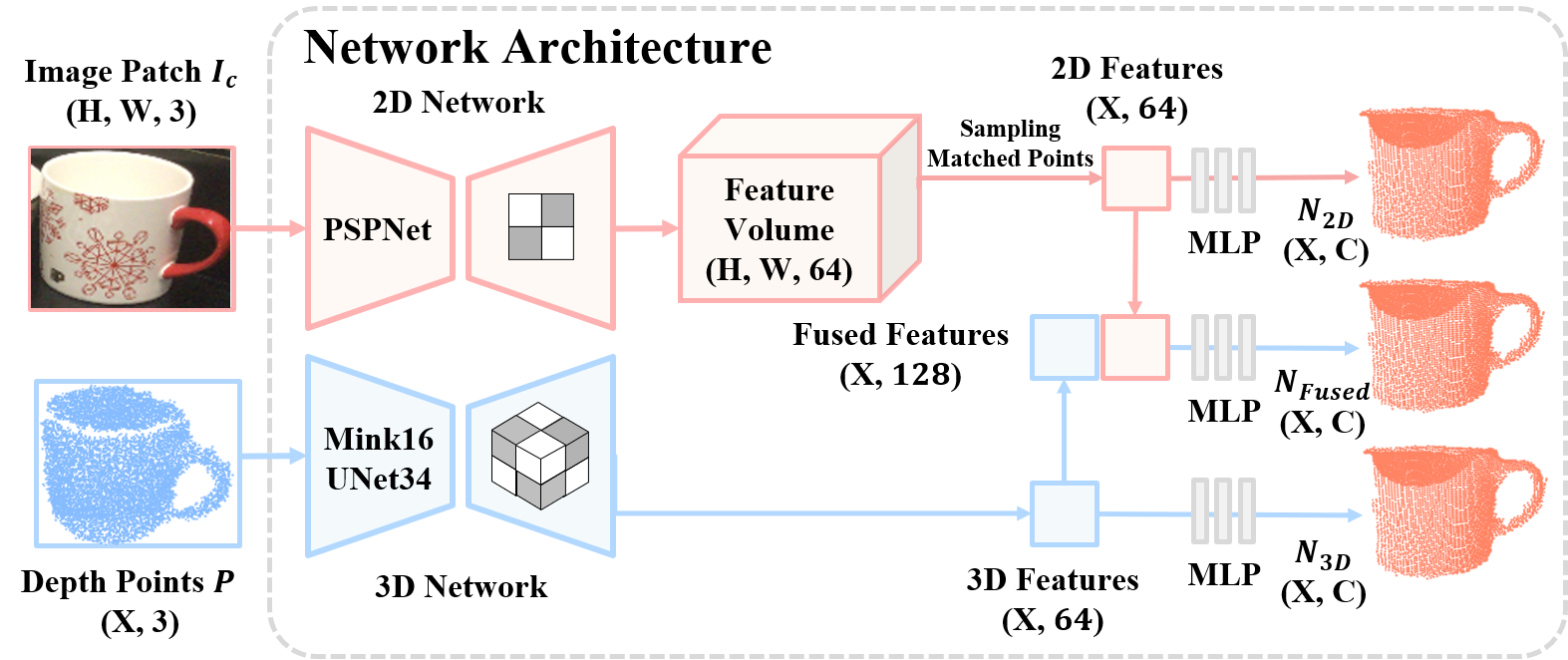
Learning to estimate object pose often requires ground-truth (GT) labels, such as CAD model and absolute-scale object pose, which is expensive and laborious to obtain in the real world. To tackle this problem, we propose an unsupervised domain adaptation (UDA) for category-level object pose estimation, called \textbf{UDA-COPE}. Inspired by the recent multi-modal UDA techniques, the proposed method exploits a teacher-student self-supervised learning scheme to train a pose estimation network without using target domain labels. We also introduce a bidirectional filtering method between predicted normalized object coordinate space (NOCS) map and observed point cloud, to not only make our teacher network more robust to the target domain but also to provide more reliable pseudo labels for the student network training. Extensive experimental results demonstrate the effectiveness of our proposed method both quantitatively and qualitatively. Notably, without leveraging target-domain GT labels, our proposed method achieves comparable or sometimes superior performance to existing methods that depend on the GT labels.
翻译:为了解决这一问题,我们提议对分类对象进行不受监督的域调整(UDA),称为\ textbf{UDA-COPE}。受最近的多模式UDA技术的启发,拟议方法利用教师-学生自我监督的学习计划,在不使用目标域名标签的情况下,训练一个组合估计网络。我们还在预测的正常物体协调空间(NOCS)地图和观测点云之间采用双向过滤方法,不仅使我们的教师网络对目标领域更加强大,而且为学生网络培训提供更可靠的假标签。广泛的实验结果表明我们拟议的方法在数量和质量上的有效性。值得注意的是,在不利用目标域名标签的情况下,我们拟议的方法取得了与依赖GT标签的现有方法相似或有时优异的绩效。