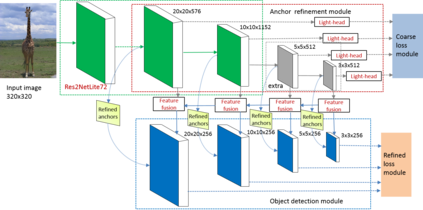
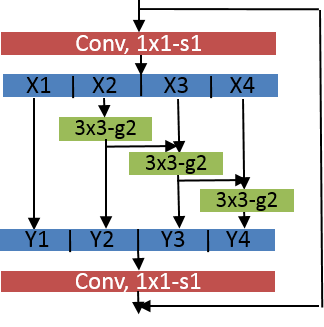
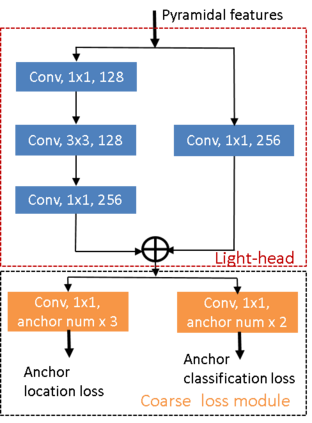
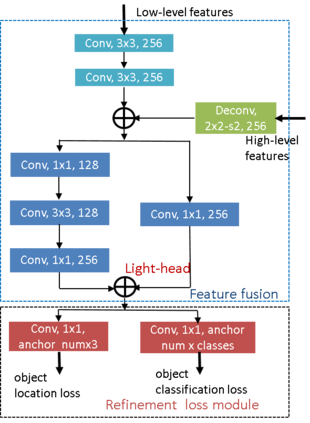
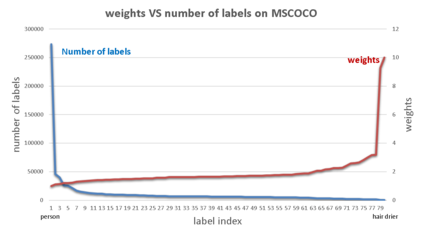
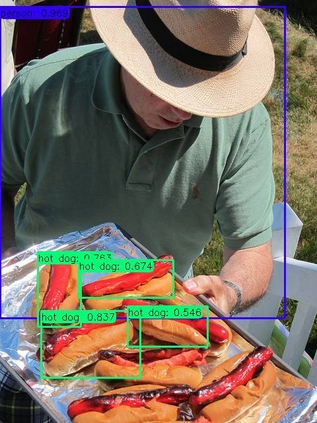
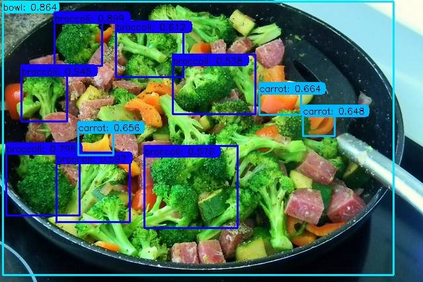
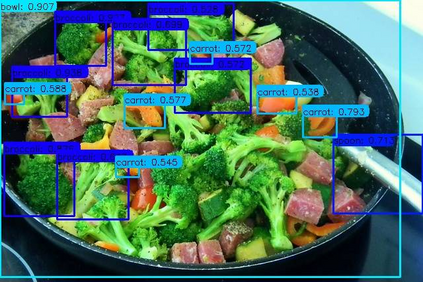
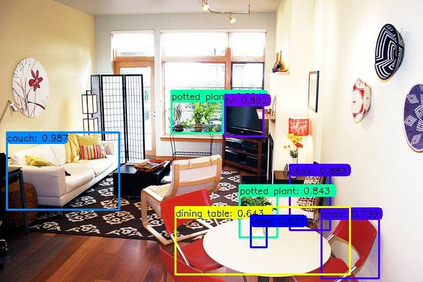
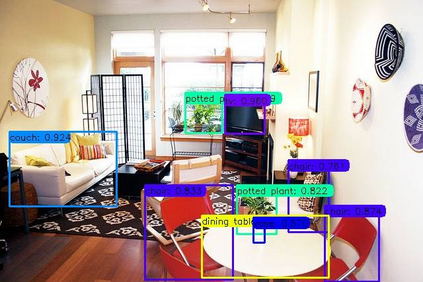
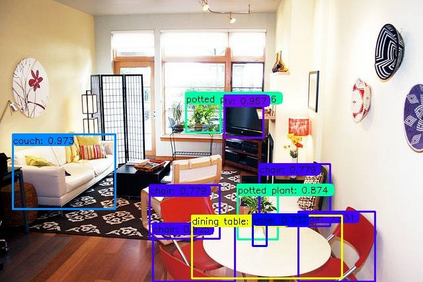
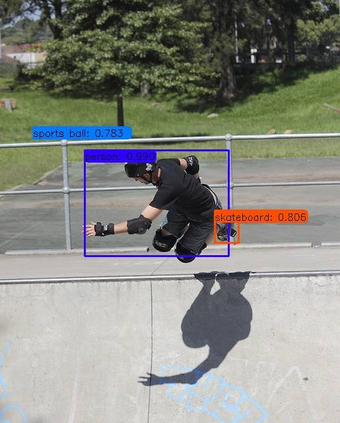
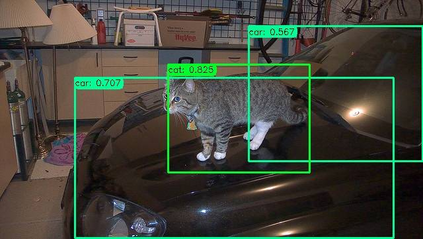
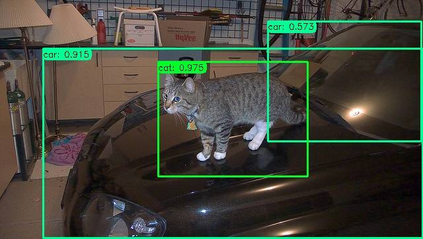
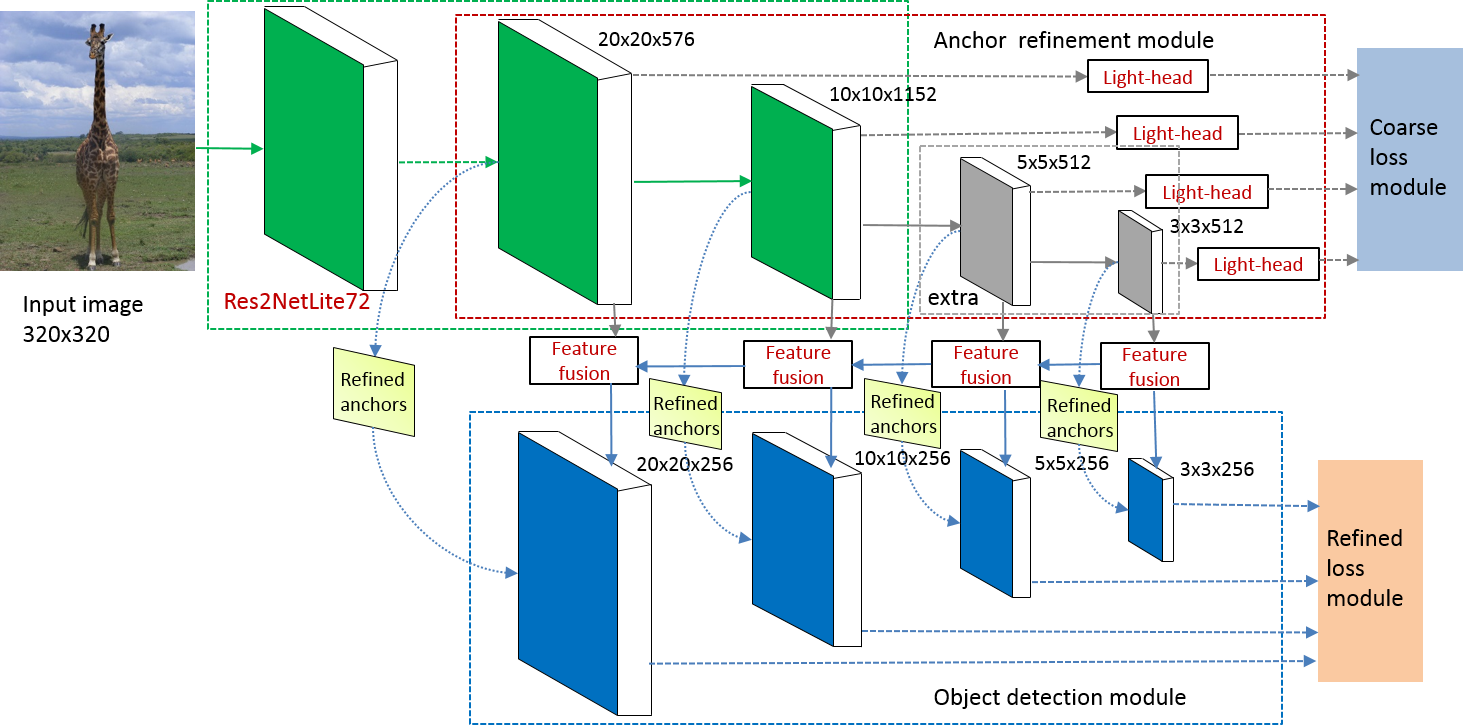
Previous state-of-the-art real-time object detectors have been reported on GPUs which are extremely expensive for processing massive data and in resource-restricted scenarios. Therefore, high efficiency object detectors on CPU-only devices are urgently-needed in industry. The floating-point operations (FLOPs) of networks are not strictly proportional to the running speed on CPU devices, which inspires the design of an exactly "fast" and "accurate" object detector. After investigating the concern gaps between classification networks and detection backbones, and following the design principles of efficient networks, we propose a lightweight residual-like backbone with large receptive fields and wide dimensions for low-level features, which are crucial for detection tasks. Correspondingly, we also design a light-head detection part to match the backbone capability. Furthermore, by analyzing the drawbacks of current one-stage detector training strategies, we also propose three orthogonal training strategies---IOU-guided loss, classes-aware weighting method and balanced multi-task training approach. Without bells and whistles, our proposed RefineDetLite achieves 26.8 mAP on the MSCOCO benchmark at a speed of 130 ms/pic on a single-thread CPU. The detection accuracy can be further increased to 29.6 mAP by integrating all the proposed training strategies, without apparent speed drop.
翻译:以往最先进的实时天体探测器在GPU上已经报告过,GPU处理大规模数据和资源限制情景极其昂贵,因此,工业迫切需要在CPU专用装置上安装高高效天体探测器。网络的浮点操作(FLOPs)与CPU装置的运行速度不完全相称,这促使设计了精确的“快”和“准确”天体探测器。在调查了分类网络和探测主干网之间的关切差距之后,并遵循高效网络的设计原则,我们建议了轻量级残余骨干,内装有大型可接收字段,低级功能宽度,对探测任务至关重要。相应地,我们还设计了一个光点探测部分,与CPU装置的运行速度不相称。此外,通过分析当前单级探测器培训战略的缺陷,我们还提议了三种骨质培训战略-IOU制损失、课堂认知加权和平衡的多任务训练方法。我们提议的REfineAPSBSBSBSBLSBS 和SLSLSLSLSLSLSLSLSLSL 直观性快速探测战略可以进一步下降。