视频目标检测:Flow-based
极市正在推出CVPR2019的专题直播分享会,邀请CVPR2019的论文作者进行线上直播,分享优秀的科研工作和技术干货,也欢迎各位小伙伴自荐或推荐优秀的CVPR论文作者到极市进行技术分享~
本周四(5月30日)晚,帝国理工学院计算机系IBUG组博士生邓健康,将为我们分享:ArcFace 构建高效的人脸识别系统(CVPR2019),公众号回复“42”即可获取直播详情。
作者简介
陀飞轮:复旦大学研究生在读,研究方向是目标检测、分割、跟踪
将图像目标检测直接应用到视频目标检测是一个巨大挑战。不同于图像,在视频中可能会产生目标外观特征的退化,比如移动模糊,视频散焦,怪异姿态等。
针对视频中的目标检测,微软提出了Flow-based的视频目标检测算法,具体如下。
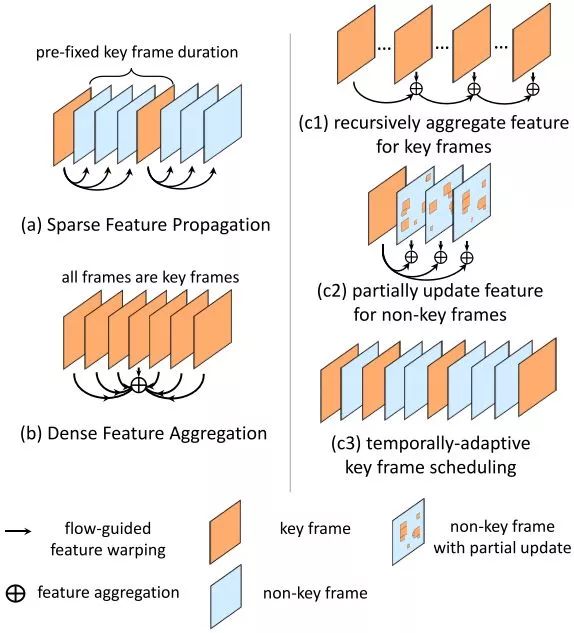
DFF主要通过提取视频中的关键帧来减小计算量提升速度(Sparse Feature Propagation)。
FGFA主要通过时序特征聚合来提升特征质量和识别精度(Multi-frame Feature Aggregation)。
THP(本文对Towards High Performance Video Object Detection的简写)提出3种策略来进一步提升速度和精度(sparsely recursive feature aggregation、spatially-adaptive partial feature updating、temporally-adaptive key frame scheduling)。
THPM(本文对Towards High Performance Video Object Detection for Mobiles的简写)通过3种策略来进一步提升速度,应用于移动端(Light Flow、Flow-guided GRU based feature aggregation、Light image object detector)。
由于THP是在DFF和FGFA的基础上进行改进的,本文将直接从THP开始,顺便回顾DFF和FGFA。
Towards High Performance Video Object Detection
Motivation
DFF使用Sparse feature propagation在大多数帧上节省计算量,在这些帧上的特征由关键帧传播得到。然而传播得到的特征仅仅是近似并且是容易出错的,这会导致识别精度的下降。
FGFA使用多帧dense feature aggregation来改善所有帧的特征质量和检测精度。然而,由于频繁的运动估计、特征传播和聚集导致运行速度很慢。
这两个工作都有一个相同原则:运动估计模块构建再网络结构里面,在所有帧端到端学习所有模块。(Flow-based的视频目标检测算法都基于这个原则)
基于这个原则,为了进一步提升速度、精度和灵活度,THP提出了3种新的策略:
1.sparsely recursive feature aggregation用来保持聚集特征的质量同时减少在关键帧的计算量。
2.spatially-adaptive partial feature updating用来更新非关键帧的特征。
3.temporally-adaptive key frame scheduling用来替换之前固定的关键帧策略。
Revisiting Two Baseline Methods on Video
Sparse Feature Propagation
DFF第一次在视频目标检测领域引入关键帧的概念,认为有相似外观的相邻帧通常导致相似的特征,因此不必要在所有帧计算特征。
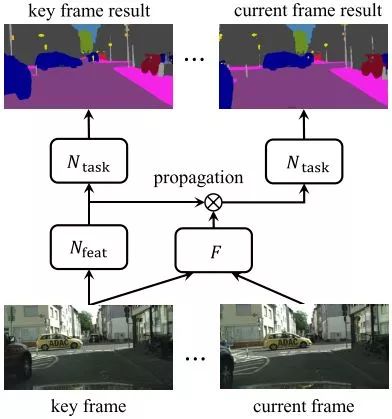
推理阶段,复杂的特征网络 







运动场通过轻量级的流网络估计得到, 



Dense Feature Aggregation
FGFA第一次在视频目标检测领域引入时序特征聚集的概念,认为在某些帧的深度特征会受到外观衰退的影响(如运动模糊,遮挡等),但是可能通过聚集邻近帧的特征来改善。
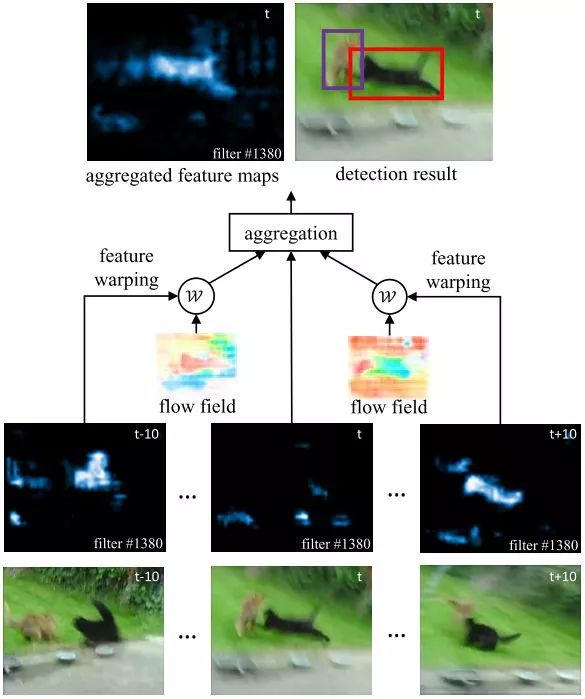
推理阶段,特征网络 

帧 

其中 





对于邻近帧,每个位置的权值都进行归一化, 
和DFF相似,所有模块端到端联合训练。
High Performance Video Object Detection
Sparsely Recursive Feature Aggregation
虽然Dense Feature Aggregation显著提升检测精度,但是速度很慢。一方面,对所有帧进行特征网络
作者提出Sparsely Recursive Feature Aggregation来估计特征网络 

其中 


原则上,聚集的关键帧特征 

Spatially-adaptive Partial Feature Updating
虽然Sparse Feature Propagation通过跟真实特征
对于非关键帧,作者想要使用特征传播的想法来进行有效计算,然而该过程依赖于传播的质量。为了量化聚集特征 

如果 


作者考虑对非关键帧进行局部特征更新,帧

其中如果 






作者使用一个直接估计器来估计梯度,如果 






为了进一步的改善非关键帧的特征质量,特征聚集可以表示为:

每个位置 
Temporally-adaptive Key Frame Scheduling
一种自然的关键帧选取策略是以预先固定的间隔选择一个关键帧。而更好的关键帧选取策略是在时间序列上自适应的动态选取。作者提出一种基于特征一致性指标

设计一种简单启发式 




A Unified Viewpoint
为了有效计算特征,使用Spatially-adaptive Partial Feature Updating(可以推广到所有帧)。给定一帧

对于关键帧, 



为了增强局部更新特征 

为了进一步改善特征计算的效率,使用Temporally-adaptive Key Frame Scheduling。
推理的流程如伪代码所示:

总结
相比于图片,视频多了一个时间维度,大多数帧的信息都是冗余的,并且目标外观特征信息不充分,因此大大增加了目标检测的计算量,并且降低了目标检测的精度。而通过Flow-based的方法,可以很自然的减少视频目标检测的冗余计算并且缓解目标外观特征退化的问题。微软的几篇工作从时间维度出发,基于流对视频目标检测算法进行改善,一步一步的提升计算效率和精度。
Reference
1.Deep Feature Flow for Video Recognition
https://arxiv.org/abs/1611.07715
2.Flow-Guided Feature Aggregation for Video Object Detection
https://arxiv.org/abs/1703.10025
3.Towards High Performance Video Object Detection
https://arxiv.org/abs/1711.11577
4.Towards High Performance Video Object Detection for Mobiles
https://arxiv.org/abs/1804.05830
欢迎交流指正~~
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~




