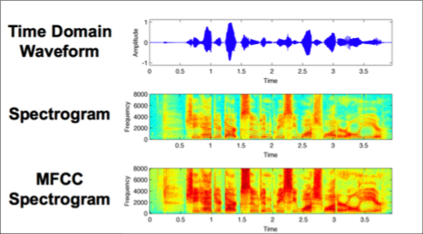
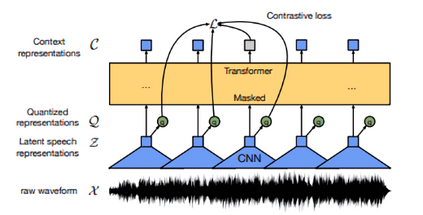
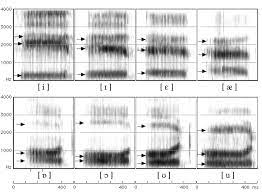
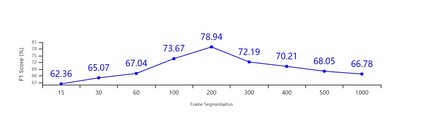
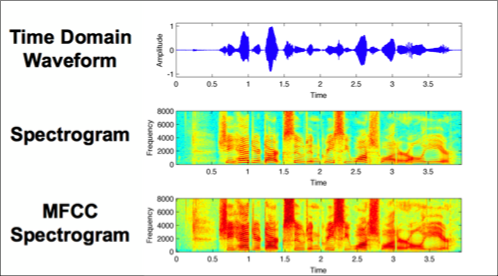
Accented speech recognition and accent classification are relatively under-explored research areas in speech technology. Recently, deep learning-based methods and Transformer-based pretrained models have achieved superb performances in both areas. However, most accent classification tasks focused on classifying different kinds of English accents and little attention was paid to geographically-proximate accent classification, especially under a low-resource setting where forensic speech science tasks usually encounter. In this paper, we explored three main accent modelling methods combined with two different classifiers based on 105 speaker recordings retrieved from five urban varieties in Northern England. Although speech representations generated from pretrained models generally have better performances in downstream classification, traditional methods like Mel Frequency Cepstral Coefficients (MFCCs) and formant measurements are equipped with specific strengths. These results suggest that in forensic phonetics scenario where data are relatively scarce, a simple modelling method and classifier could be competitive with state-of-the-art pretrained speech models as feature extractors, which could enhance a sooner estimation for the accent information in practices. Besides, our findings also cross-validated a new methodology in quantifying sociophonetic changes.
翻译:语音识别和口音分类是语言技术中相对不足的研究领域。最近,深层次的学习方法和基于变异器的预先培训模型在这两个领域都取得了超优成绩。然而,大多数重音分类任务侧重于对不同类型的英语口音进行分类,而很少注意地理上接近口音分类,特别是在法医语言科学任务通常遇到的低资源环境下。在本文件中,我们探讨了三种主要口音建模方法,以及基于从英格兰北部五种城市品种中检索的105个发言者录音记录的两个不同的分类方法。尽管预先培训模型的语音表述在下游分类中通常有更好的表现,但传统方法,如Mel频缓冲节能(Mel Cepstravalys)和成型测量都具备了具体优势。这些结果表明,在数据相对稀少的法医学语音假设中,简单的建模方法和叙级器可以与作为特征提取器的州级预先培训的语音模型具有竞争力,这可以提高实践中对口音信息的快速估计。此外,我们的调查结果还交叉评价了用新的方法来量化社会语言变化。