成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
文本分类
关注
350
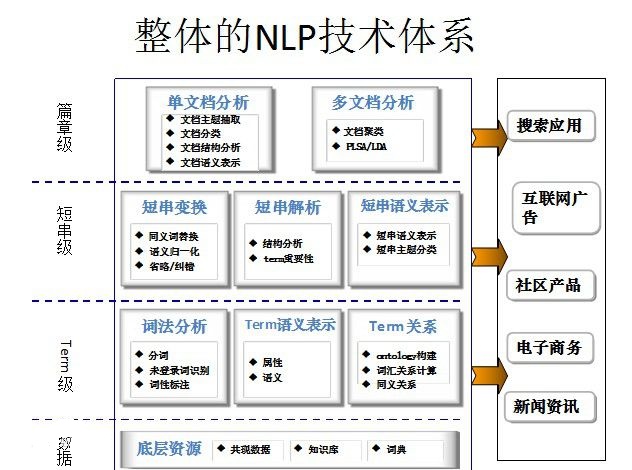
文本分类(Text Classification)任务是根据给定文档的内容或主题,自动分配预先定义的类别标签。
综合
百科
VIP
热门
动态
论文
精华
精品内容
领域特定文本分类中的预训练语言模型新进展:系统综述
专知会员服务
12+阅读 · 10月24日
【博士论文】针对基于文本的基础模型的分类偏差分析与缓解
专知会员服务
15+阅读 · 3月10日
文本分类算法及其应用场景研究
专知会员服务
19+阅读 · 2024年7月31日
文本分类算法及其应用场景研究综述
专知会员服务
29+阅读 · 2024年6月18日
《主动社会工程防御(ASED)计划中的综合数据驱动解决方案(I2DS)项目》美空军实验室报告
专知会员服务
14+阅读 · 2024年5月21日
基于深度学习的中文文本分类综述
专知会员服务
25+阅读 · 2024年5月9日
【MIT博士论文】可部署的鲁棒文本分类器
专知会员服务
27+阅读 · 2023年5月4日
首篇《图神经网络文本分类》2023综述,详述二十种GNN文本分类模型
专知会员服务
60+阅读 · 2023年5月1日
基于图卷积神经网络的文本分类方法研究综述
专知会员服务
40+阅读 · 2022年8月26日
监督和半监督学习下的多标签分类综述
专知会员服务
46+阅读 · 2022年8月3日
【COMPTEXT2022教程】跨语言监督文本分类,41页ppt
专知会员服务
18+阅读 · 2022年6月14日
【KDD2022】海量文本语料库中的无监督关键事件检测
专知会员服务
33+阅读 · 2022年6月13日
【Facebook AI】fastText是一个用于高效学习单词表示和句子分类的库
专知会员服务
22+阅读 · 2022年3月25日
【AAAI2022】基于协调域编码器和配对分类器的多源域适应
专知会员服务
17+阅读 · 2022年2月9日
【AAAI2022】联合文本分类和关系提取的统一模型可解释性和鲁棒性
专知会员服务
19+阅读 · 2021年12月30日
参考链接
父主题
自然语言处理应用研究
子主题
BERT多标签分类
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top