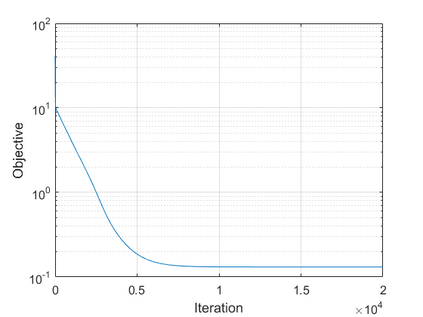
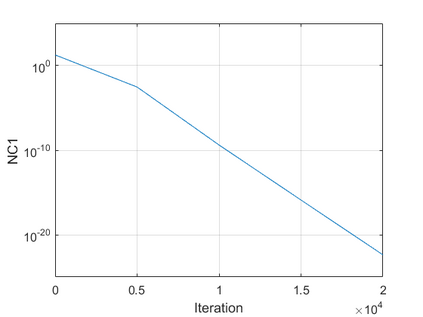
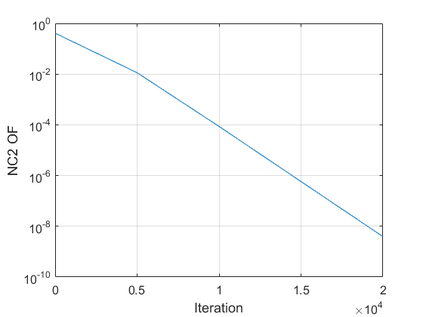
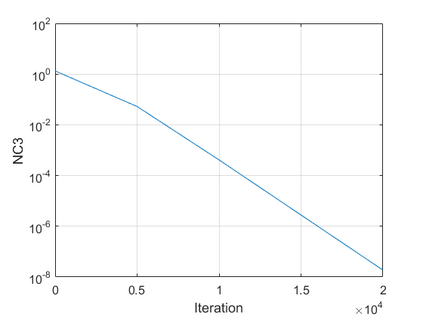
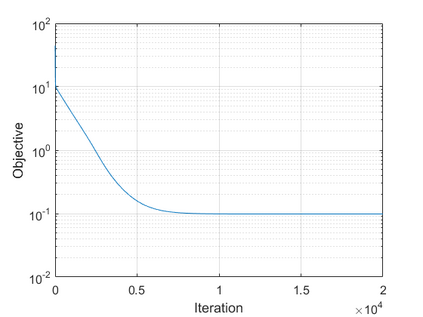
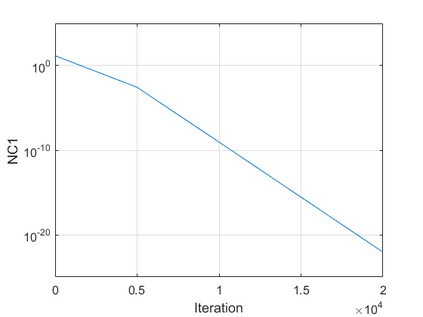
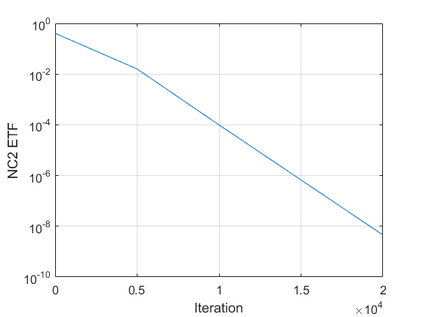
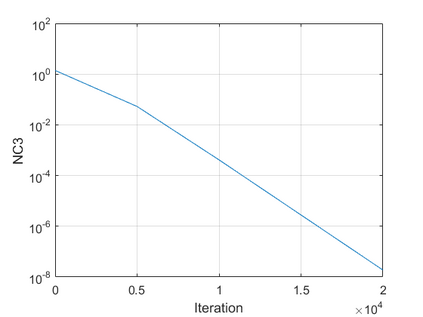
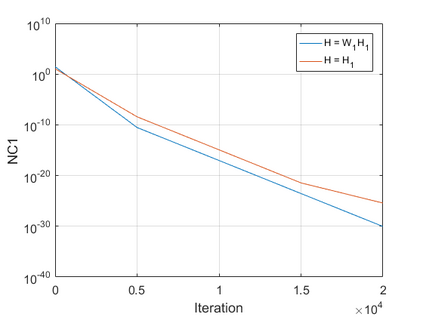
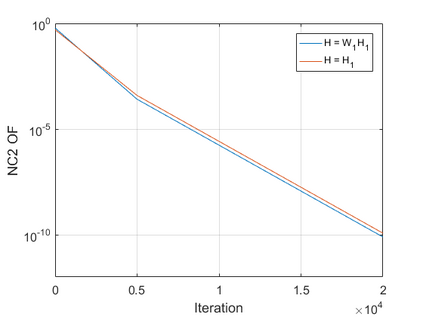
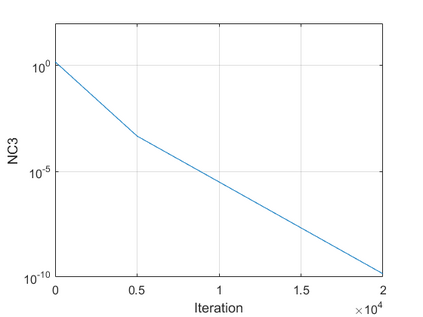
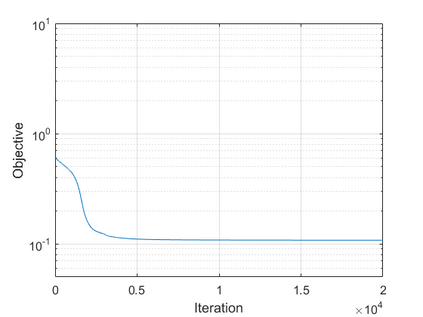
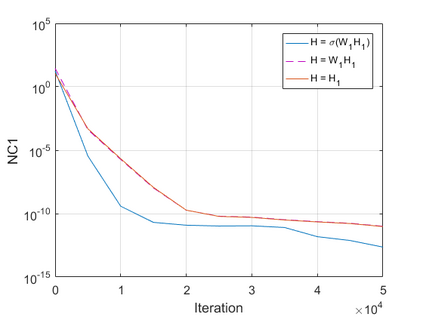
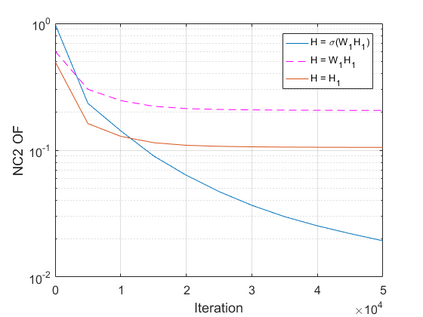
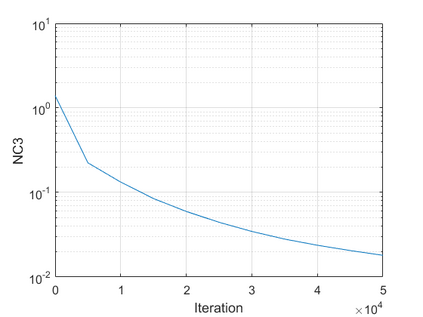
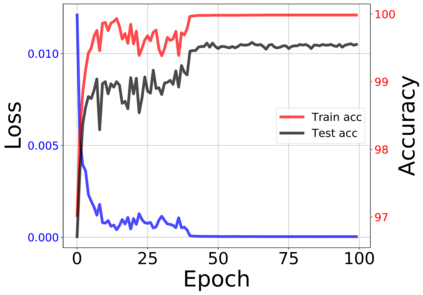
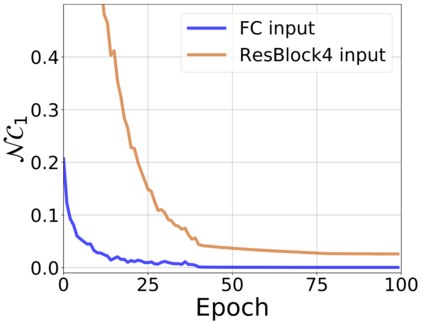
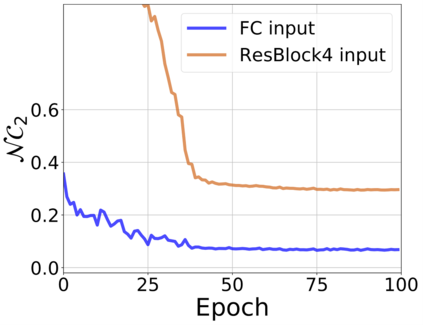
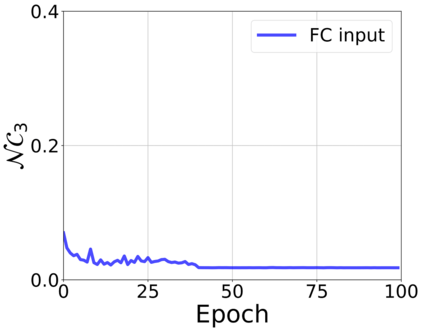
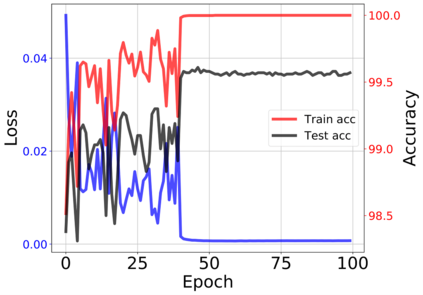
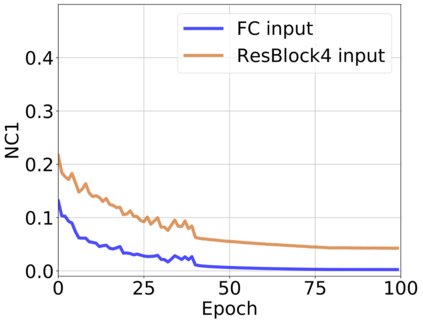
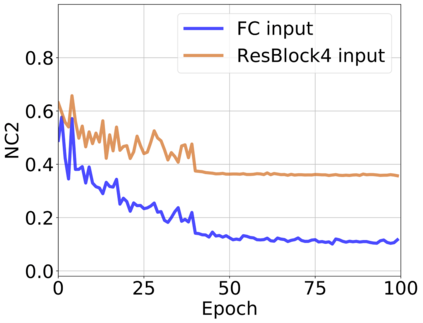
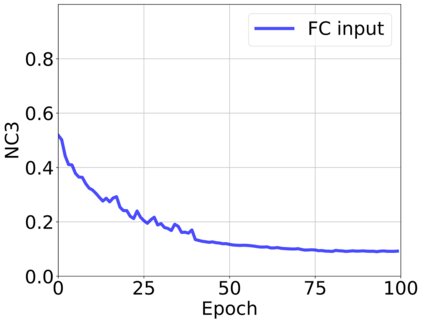
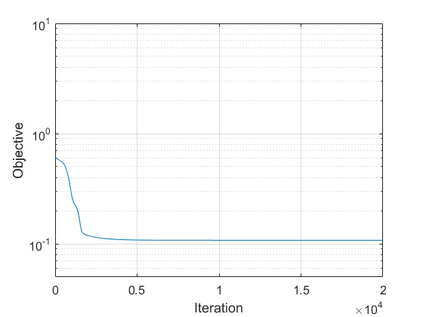
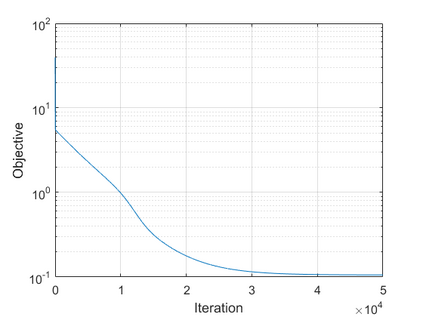
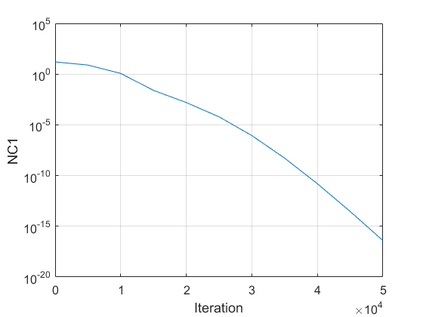
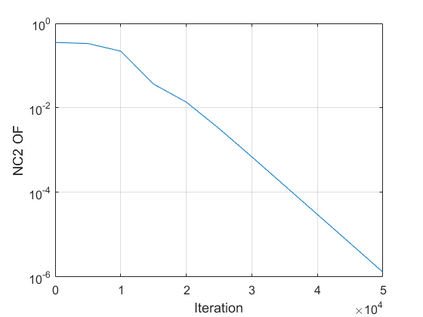
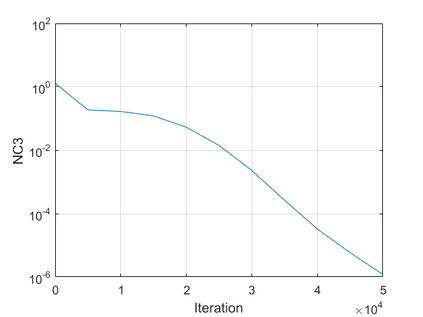
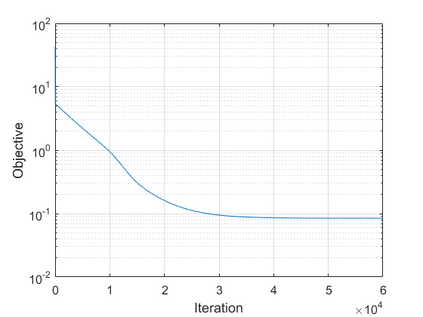
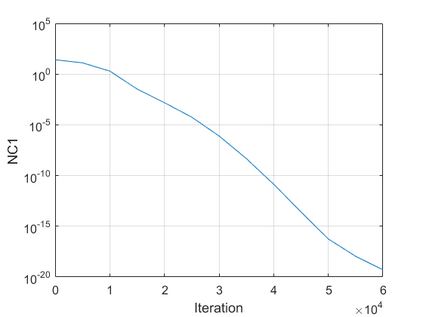
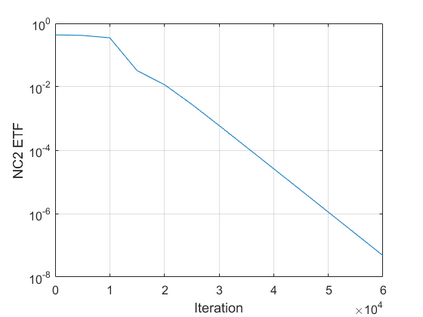
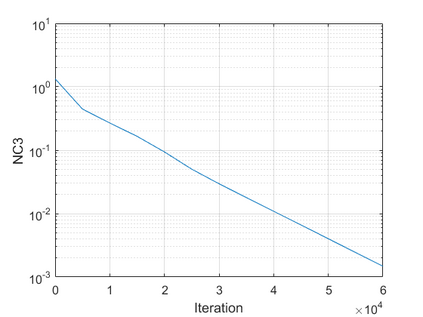
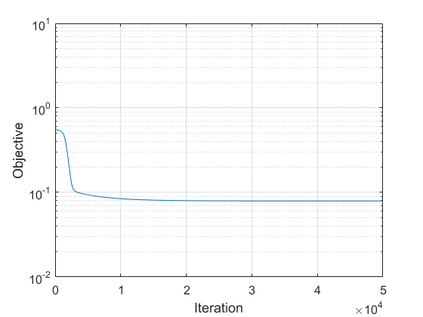
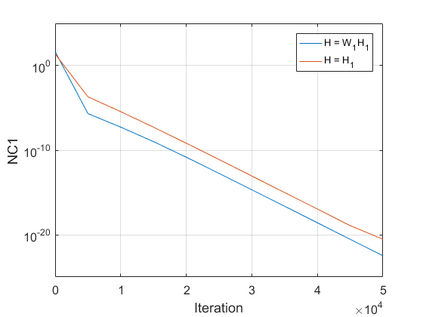
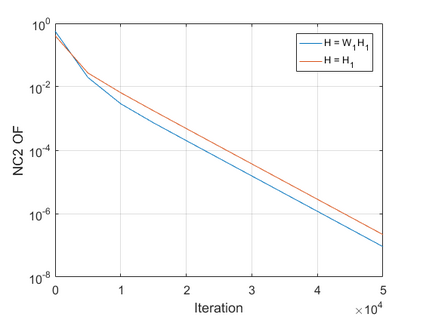
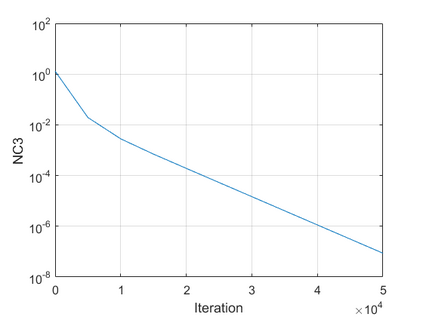
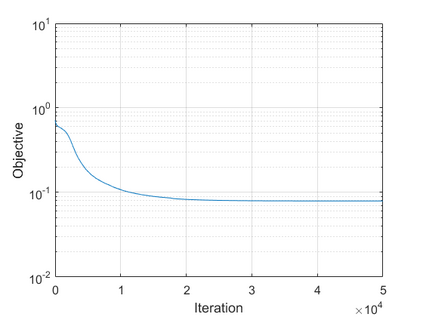
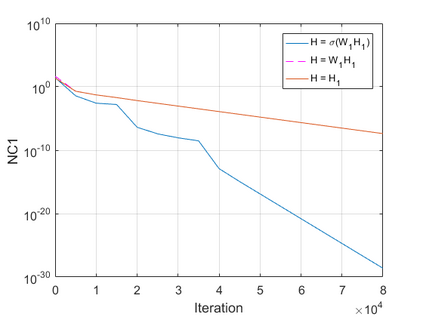
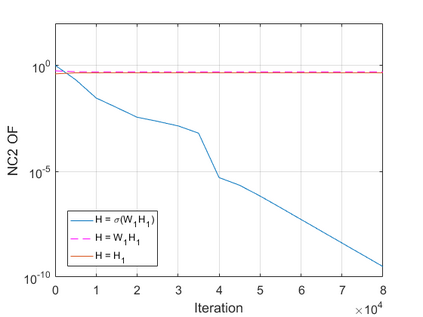
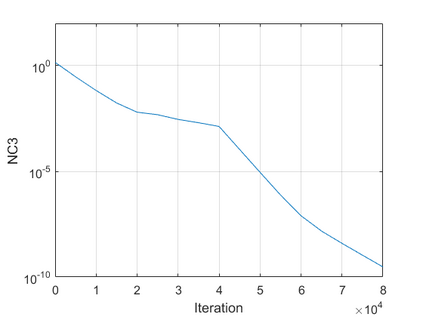
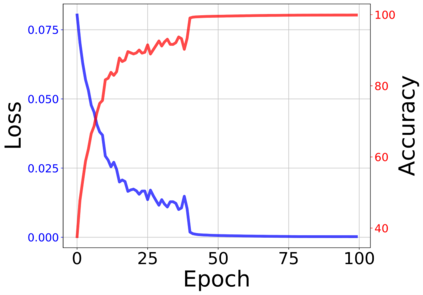
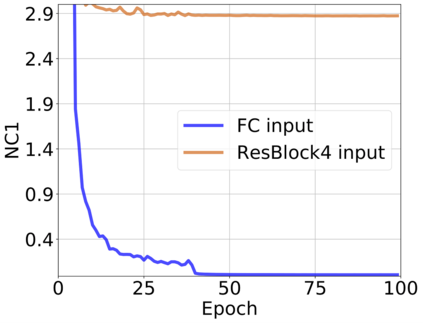
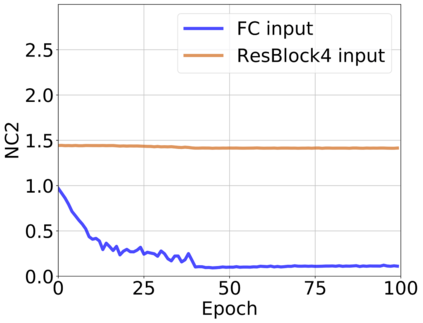
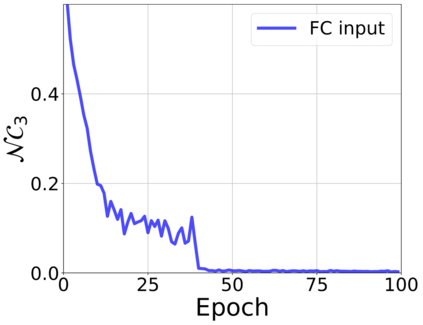
The modern strategy for training deep neural networks for classification tasks includes optimizing the network's weights even after the training error vanishes to further push the training loss toward zero. Recently, a phenomenon termed "neural collapse" (NC) has been empirically observed in this training procedure. Specifically, it has been shown that the learned features (the output of the penultimate layer) of within-class samples converge to their mean, and the means of different classes exhibit a certain tight frame structure, which is also aligned with the last layer's weights. Recent papers have shown that minimizers with this structure emerge when optimizing a simplified "unconstrained features model" (UFM) with a regularized cross-entropy loss. In this paper, we further analyze and extend the UFM. First, we study the UFM for the regularized MSE loss, and show that the minimizers' features can be more structured than in the cross-entropy case. This affects also the structure of the weights. Then, we extend the UFM by adding another layer of weights as well as ReLU nonlinearity to the model and generalize our previous results. Finally, we empirically demonstrate the usefulness of our nonlinear extended UFM in modeling the NC phenomenon that occurs with practical networks.
翻译:为分类任务培训深神经网络的现代战略包括优化网络的重量,即使培训错误消失后网络的重量,以将培训损失进一步推向零。最近,在这一培训过程中,从经验中观察到了一个名为“神经崩溃”的现象。具体地说,已经表明,本类样本的学习特点(倒数第二层的产出)与其平均值一致,不同类别的方法也表现出某种紧凑的框架结构,这也与最后一层的重量相一致。最近的文件表明,在优化一个简化的“不受限制特征模型”(UFM)时,这一结构的最小化作用会显现出来,该模型具有常规化的跨热带损失。在本文件中,我们进一步分析并扩展了UFMM。首先,我们研究固定化的 MSE损失的UM特性(倒数倒数倒数倒数第二层的产出),并表明,最小化器的特性比跨层的重量结构要好一些。然后,我们通过增加另一层的重量和RELU的非线性能到模型中去,然后我们用NCFM的模型展示了我们以往的实用性能模型。