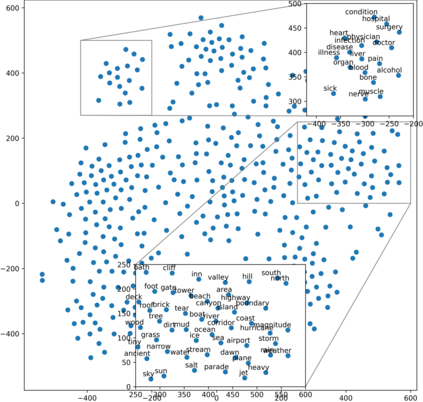
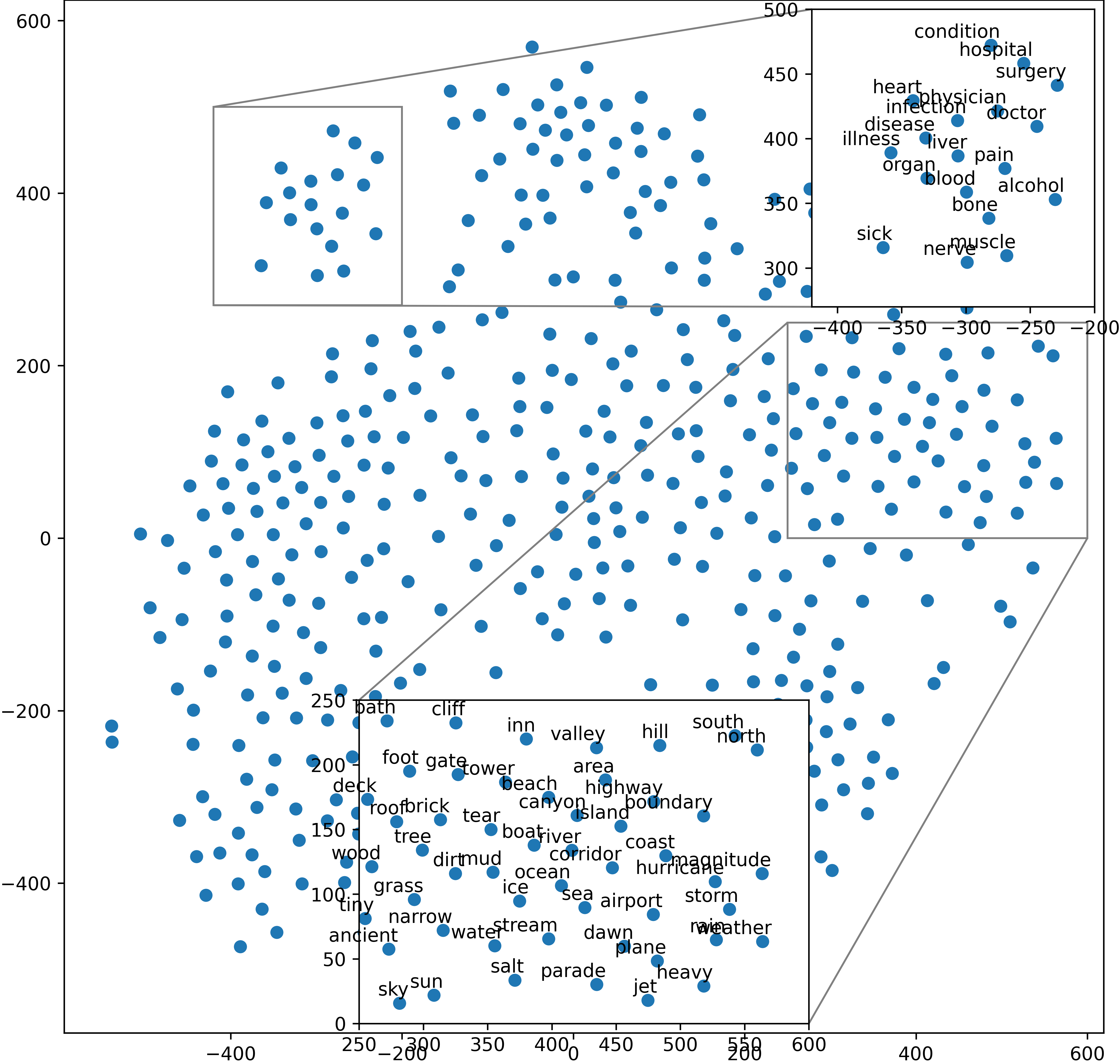
Embedding words in vector space is a fundamental first step in state-of-the-art natural language processing (NLP). Typical NLP solutions employ pre-defined vector representations to improve generalization by co-locating similar words in vector space. For instance, Word2Vec is a self-supervised predictive model that captures the context of words using a neural network. Similarly, GLoVe is a popular unsupervised model incorporating corpus-wide word co-occurrence statistics. Such word embedding has significantly boosted important NLP tasks, including sentiment analysis, document classification, and machine translation. However, the embeddings are dense floating-point vectors, making them expensive to compute and difficult to interpret. In this paper, we instead propose to represent the semantics of words with a few defining words that are related using propositional logic. To produce such logical embeddings, we introduce a Tsetlin Machine-based autoencoder that learns logical clauses self-supervised. The clauses consist of contextual words like "black," "cup," and "hot" to define other words like "coffee," thus being human-understandable. We evaluate our embedding approach on several intrinsic and extrinsic benchmarks, outperforming GLoVe on six classification tasks. Furthermore, we investigate the interpretability of our embedding using the logical representations acquired during training. We also visualize word clusters in vector space, demonstrating how our logical embedding co-locate similar words.
翻译:矢量空间中的嵌入字是最新自然语言处理( NLP) 最基本的第一步。 典型的 NLP 解决方案使用预先定义的矢量表达方式, 通过在矢量空间中共同定位相似的字词来改进一般化。 例如, Word2Vec 是一个自我监督的预测模型, 能够捕捉使用神经网络的字语背景。 同样, GloVe 是一个流行且不受监督的模式, 包含了全组织范围内的单词共生统计。 这种嵌入字大大促进了重要的 NLP 任务, 包括情绪分析、 文件分类和机器翻译。 然而, 嵌入的矢量是密集的浮点矢量, 使得它们具有昂贵的可拼释和难以解释的类似词。 在本文中, 我们提议用一些定义词的语义, 以逻辑嵌入方式学习逻辑条款自我超越。 条款包括“ black, cuput, ” 和“hostappilable” 等背景词, 用来定义其它的内嵌化定义“ 我们的内嵌化” 。