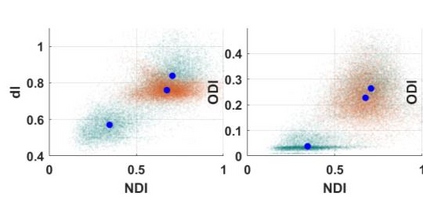
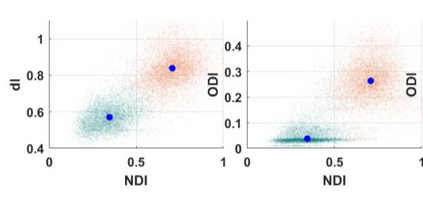
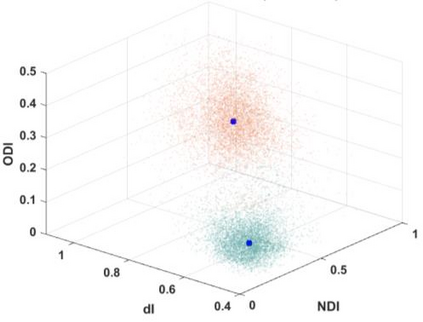
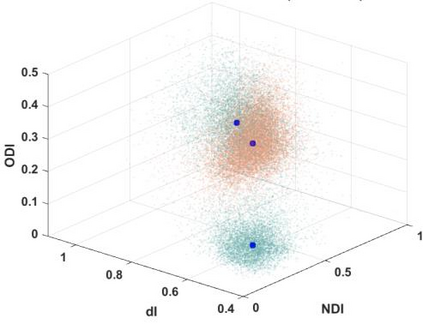
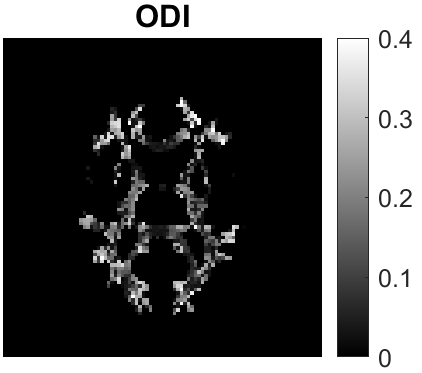
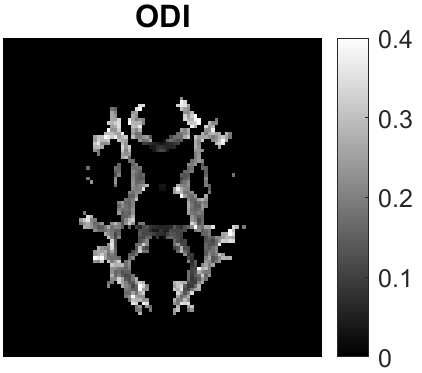
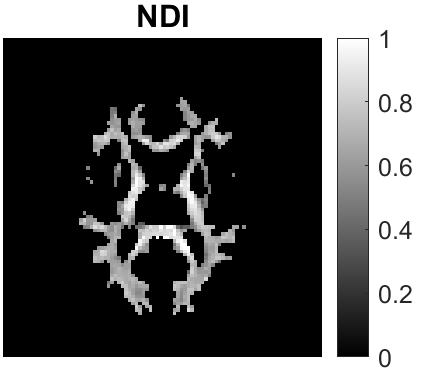
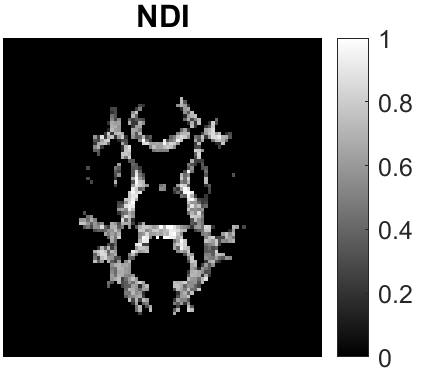
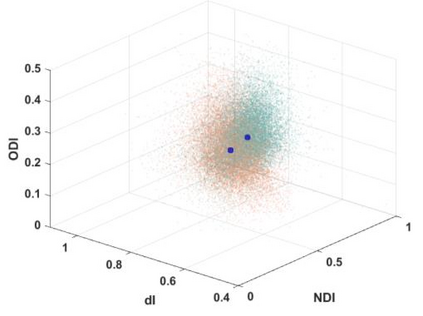
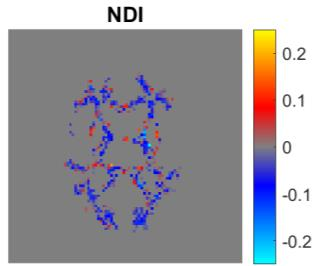
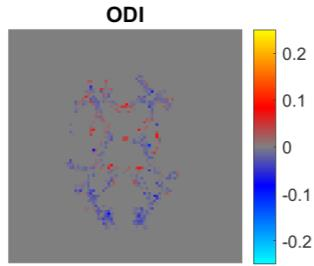
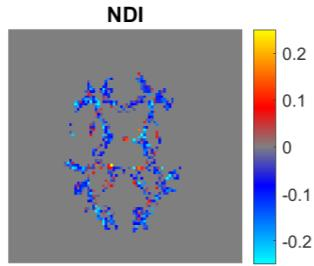
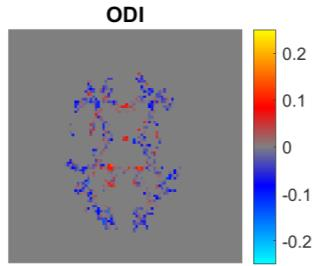
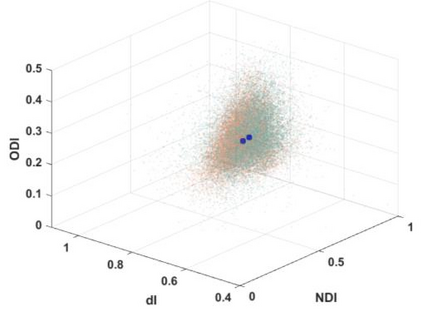
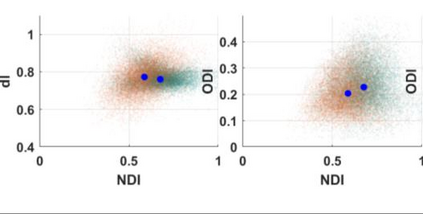
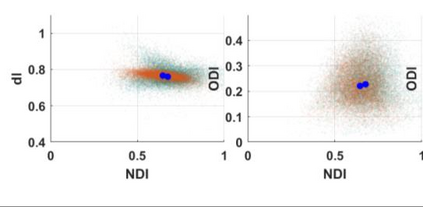
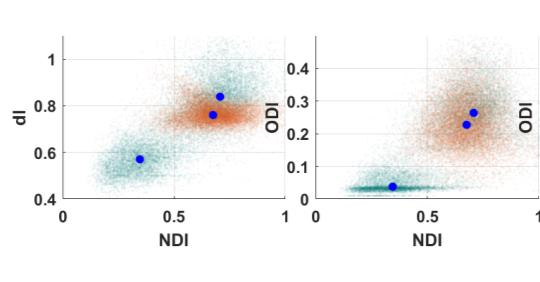
Quantitative MRI (qMRI) aims to map tissue properties non-invasively via models that relate these unknown quantities to measured MRI signals. Estimating these unknowns, which has traditionally required model fitting - an often iterative procedure, can now be done with one-shot machine learning (ML) approaches. Such parameter estimation may be complicated by intrinsic qMRI signal model degeneracy: different combinations of tissue properties produce the same signal. Despite their many advantages, it remains unclear whether ML approaches can resolve this issue. Growing empirical evidence appears to suggest ML approaches remain susceptible to model degeneracy. Here we demonstrate under the right circumstances ML can address this issue. Inspired by recent works on the impact of training data distributions on ML-based parameter estimation, we propose to resolve model degeneracy by designing training data distributions. We put forward a classification of model degeneracies and identify one particular kind of degeneracies amenable to the proposed attack. The strategy is demonstrated successfully using the Revised NODDI model with standard multi-shell diffusion MRI data as an exemplar. Our results illustrate the importance of training set design which has the potential to allow accurate estimation of tissue properties with ML.
翻译:定量 MRI (qMRI) 旨在通过模型绘制组织属性,这些未知数量与测量的 MRI 信号相关,这些未知数量与测量的 MRI 信号相关,通过模型显示组织属性的不侵扰性。估计这些未知情况,这些未知情况历来需要模型的安装 -- -- 通常是迭代程序,现在可以通过一次性机器学习(ML)方法进行。这种参数估计可能因内在的 qMRI 信号模型脱精性而变得复杂:不同的组织属性组合产生同样的信号。尽管它们有许多优点,但仍不清楚ML 方法能否解决这个问题。越来越多的实证证据似乎表明ML 方法仍然易受模型变异性的影响。在这里,我们证明ML 可以在正确的情况下解决这一问题。根据最近关于基于 ML 参数估算的培训数据发布的影响的工作,我们提议通过设计培训数据分布来解决模型变精度问题。我们提出了模型变精度分类,并确定了适合拟议攻击的某种特定的脱精度。我们成功地运用了订正的 NODDI DI 模型和标准的多壳扩散 MIR 数据作为exmplar 的缩略图。我们的成果展示了培训设置的重要性。</s>