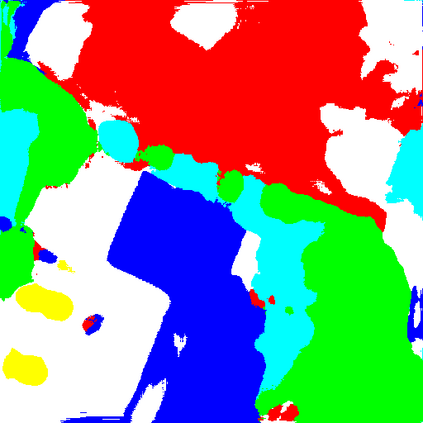
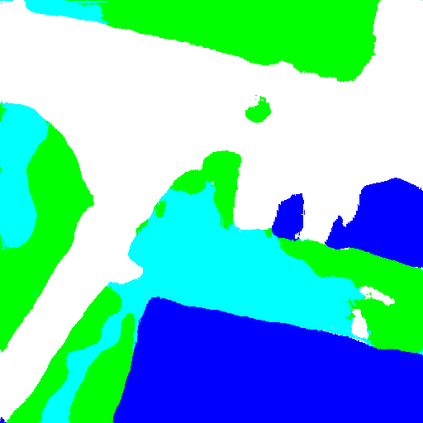
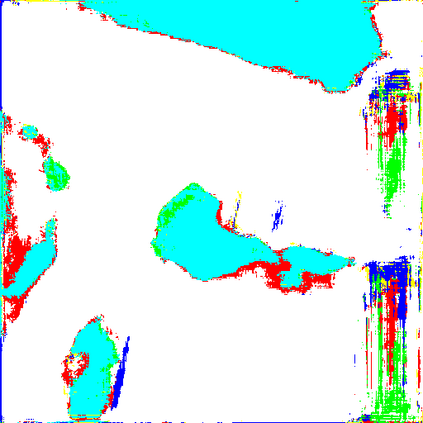
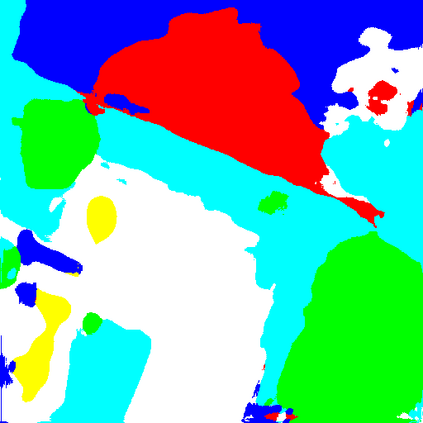
Domain adaptation is one of the prominent strategies for handling both domain shift, that is widely encountered in large-scale land use/land cover map calculation, and the scarcity of pixel-level ground truth that is crucial for supervised semantic segmentation. Studies focusing on adversarial domain adaptation via re-styling source domain samples, commonly through generative adversarial networks, have reported varying levels of success, yet they suffer from semantic inconsistencies, visual corruptions, and often require a large number of target domain samples. In this letter, we propose a new unsupervised domain adaptation method for the semantic segmentation of very high resolution images, that i) leads to semantically consistent and noise-free images, ii) operates with a single target domain sample (i.e. one-shot) and iii) at a fraction of the number of parameters required from state-of-the-art methods. More specifically an image-to-image translation paradigm is proposed, based on an encoder-decoder principle where latent content representations are mixed across domains, and a perceptual network module and loss function is further introduced to enforce semantic consistency. Cross-city comparative experiments have shown that the proposed method outperforms state-of-the-art domain adaptation methods. Our source code will be available at \url{https://github.com/Sarmadfismael/LRM_I2I}.
翻译:在大规模土地利用/土地覆盖地图的计算过程中,广泛遇到的处理领域转移以及缺乏对受监督的语义分割至关重要的像素级地面真象的缺乏等离子级地面真象问题,主要通过基因对抗网络,侧重于通过重新拼写源域样本进行对抗性域别调整的研究,报告取得了不同程度的成功,但是它们受到语义不一致和视觉腐败的影响,而且往往需要大量的目标域抽样。在本信中,我们提议为甚高分辨率图像的语义分解采用一种新的不受监督的域域适应方法,i)导致语义上的一致性和无噪音图像,ii)以单一目标域样(即一发)和iii)的对抗性域性调整研究,这些研究通常通过基因对抗性对抗性对抗性对抗性对抗性对抗性源域域域域域抽样,通常通过基因对抗性对抗性对抗性对抗性网络网络网络的网络样板,这些区域图解的图象-图象变异形翻译范则基于隐含内容的域图象-变形学原则,以及概念性网络模块和损失函数功能将进一步在区域内进行比较性实验。