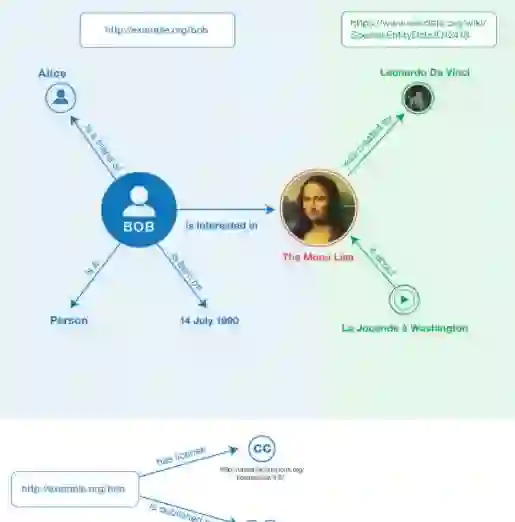
The increasing availability of semantic data has substantially enhanced Web applications. Semantic data such as RDF data is commonly represented as entity-property-value triples. The magnitude of semantic data, in particular the large number of triples describing an entity, could overload users with excessive amounts of information. This has motivated fruitful research on automated generation of summaries for entity descriptions to satisfy users' information needs efficiently and effectively. We focus on this prominent topic of entity summarization, and our research objective is to present the first comprehensive survey of entity summarization research. Rather than separately reviewing each method, our contributions include (1) identifying and classifying technical features of existing methods to form a high-level overview, (2) identifying and classifying frameworks for combining multiple technical features adopted by existing methods, (3) collecting known benchmarks for intrinsic evaluation and efforts for extrinsic evaluation, and (4) suggesting research directions for future work. By investigating the literature, we synthesized two hierarchies of techniques. The first hierarchy categories generic technical features into several perspectives: frequency and centrality, informativeness, and diversity and coverage. In the second hierarchy we present domain-specific and task-specific technical features, including the use of domain knowledge, context awareness, and personalization. Our review demonstrated that existing methods are mainly unsupervised and they combine multiple technical features using various frameworks: random surfer models, similarity-based grouping, MMR-like re-ranking, or combinatorial optimization. We also found a few deep learning based methods in recent research.
翻译:语义数据(例如RDF数据)通常被作为实体-财产价值的三重值。语义数据的规模,特别是描述一个实体的三重数据数量之大,可能使用户过多的信息量过大。这促使对自动生成实体描述摘要以满足用户的信息需求进行了富有成果的研究。我们集中关注实体汇总这一突出的课题,我们的研究目标是提出实体汇总研究的首次全面调查。我们的贡献不是单独审查每一种方法,而是包括:(1) 确定和分类现有方法的技术特征,形成高级别概览;(2) 确定和分类将现有方法所采用的多种技术特征结合起来的框架,(3) 收集已知的内在评估和外部评估工作基准,(4) 为今后的工作建议研究方向。我们通过研究文献,综合了两个技术等级。我们的研究目标是从若干角度介绍基于等级的通用技术特征:频率和中心、信息性、多样性和覆盖范围。 在第二个等级中,我们介绍最近具体领域和具体任务对当前方法的技术特征的组合,主要包括使用各种基于领域知识的实地评估,以及现有技术特征。