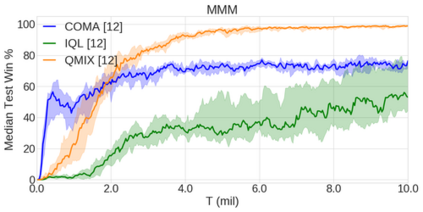
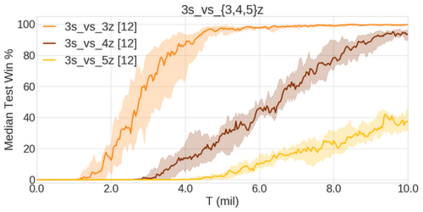
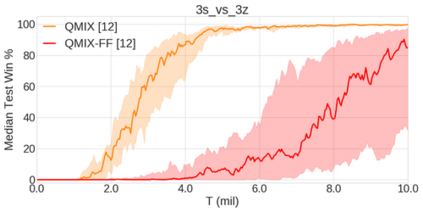
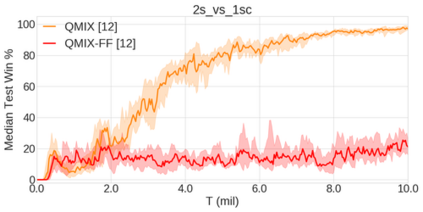
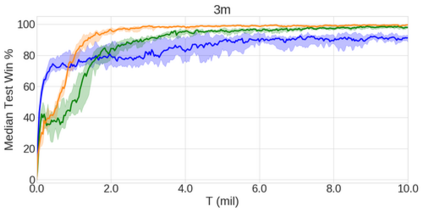
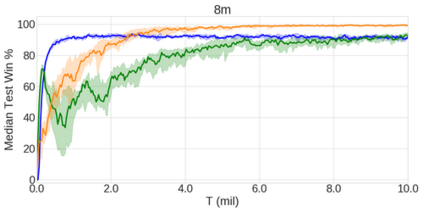
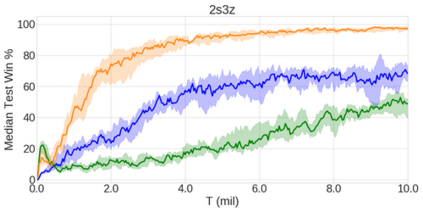
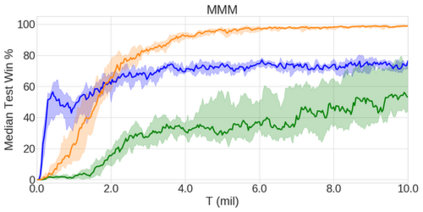
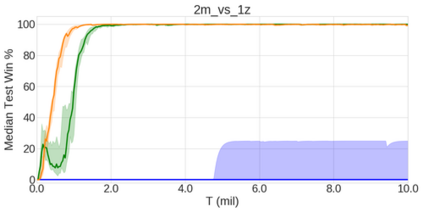
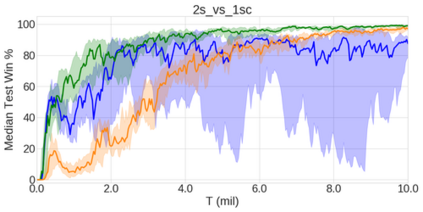
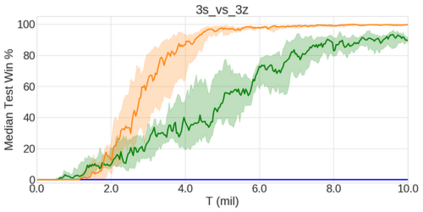
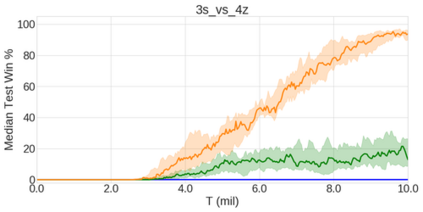
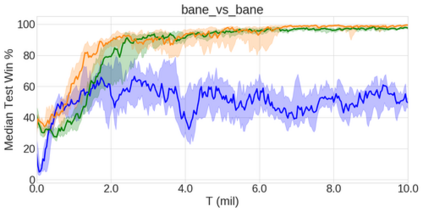
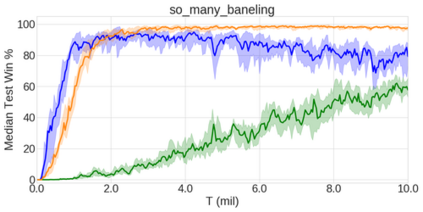
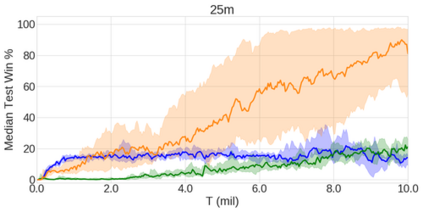
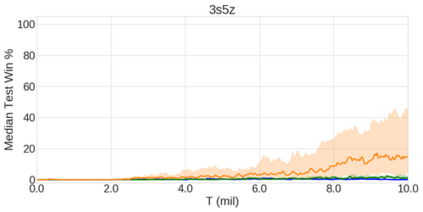
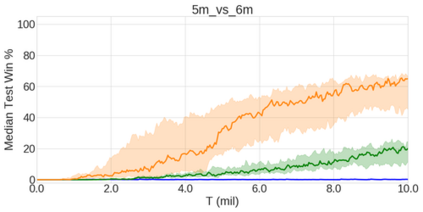
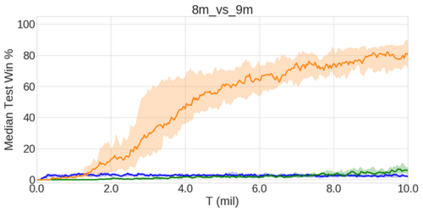
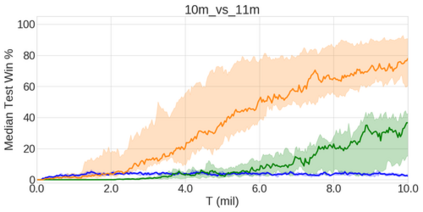
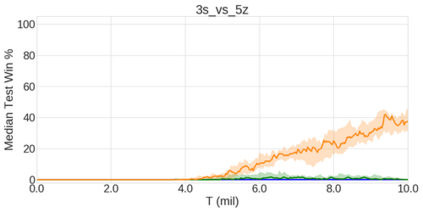
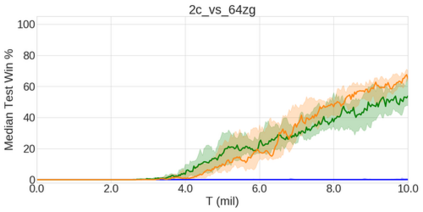
In the last few years, deep multi-agent reinforcement learning (RL) has become a highly active area of research. A particularly challenging class of problems in this area is partially observable, cooperative, multi-agent learning, in which teams of agents must learn to coordinate their behaviour while conditioning only on their private observations. This is an attractive research area since such problems are relevant to a large number of real-world systems and are also more amenable to evaluation than general-sum problems. Standardised environments such as the ALE and MuJoCo have allowed single-agent RL to move beyond toy domains, such as grid worlds. However, there is no comparable benchmark for cooperative multi-agent RL. As a result, most papers in this field use one-off toy problems, making it difficult to measure real progress. In this paper, we propose the StarCraft Multi-Agent Challenge (SMAC) as a benchmark problem to fill this gap. SMAC is based on the popular real-time strategy game StarCraft II and focuses on micromanagement challenges where each unit is controlled by an independent agent that must act based on local observations. We offer a diverse set of challenge maps and recommendations for best practices in benchmarking and evaluations. We also open-source a deep multi-agent RL learning framework including state-of-the-art algorithms. We believe that SMAC can provide a standard benchmark environment for years to come. Videos of our best agents for several SMAC scenarios are available at: https://youtu.be/VZ7zmQ_obZ0.
翻译:在过去几年里,深层多试剂强化学习(RL)已成为一个非常活跃的研究领域。该领域特别具有挑战性的一类问题是部分可见的、合作的、多试剂的学习,在这一学习中,代理人团队必须学会协调其行为,同时仅以其私人观察为条件。这是一个有吸引力的研究领域,因为这些问题与大量实际世界系统相关,比一般和问题更容易受到评价。标准化的环境,如ALE和MuJoCo,使单一代理人RL能够超越诸如网格世界等互不相干的领域。然而,没有合作多试剂RL的可比基准。结果,这个领域的多数文件使用一反的、难于衡量真正的进展。我们在此文件中建议StarCraft多试挑战(SMAAC)作为弥补这一差距的基准问题的基准。Star-Cft StarCratoft II以流行的实时战略游戏为基础,并侧重于微观管理的挑战,其中每个单位都由独立代理人根据当地观察来控制。我们在实地观察中提供一套不同的方法,包括S-R-R-R-R-R-R-assimal Ral 标准的图表和S-assal-assal 标准框架。我们可以提供一套最佳的、我们关于S-r-r-r-r-r-r-r-ass-ass-ass-ass-assal-assal-labal-lab-ass-ass-vial-ass-ass-ass-viol-