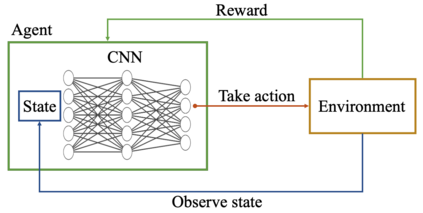
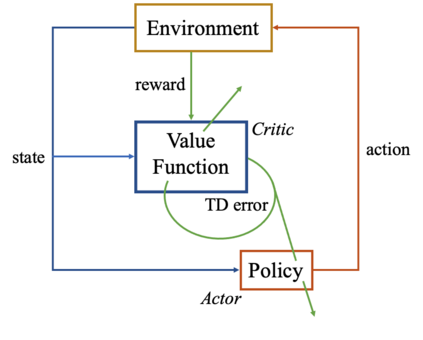
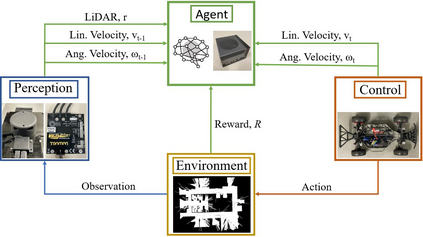
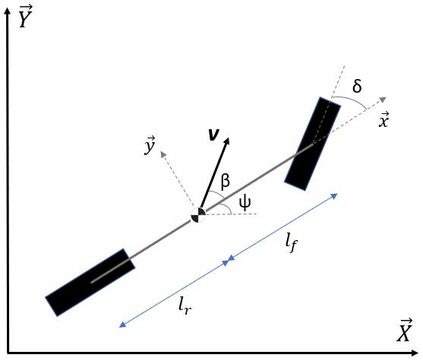
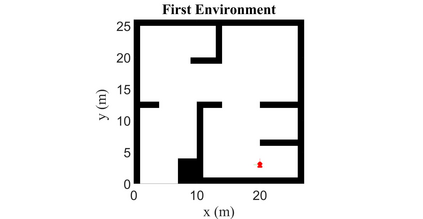
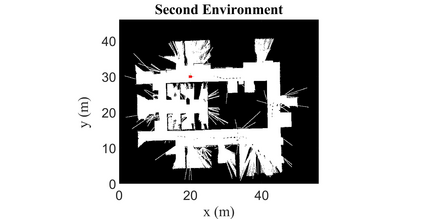
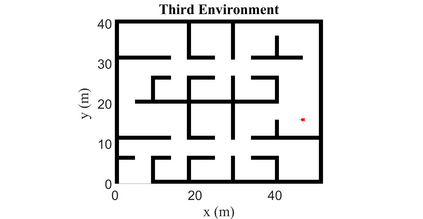
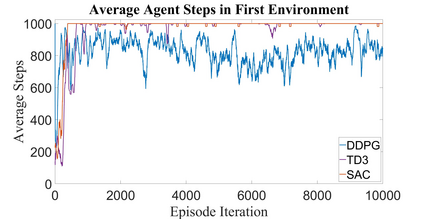
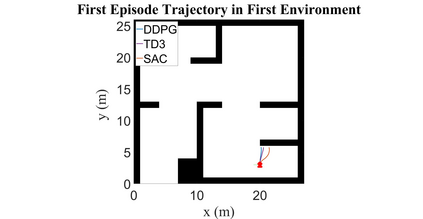
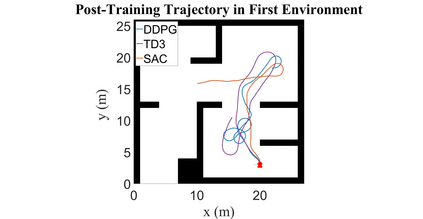
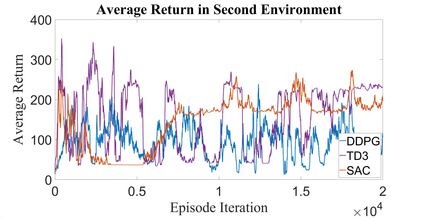
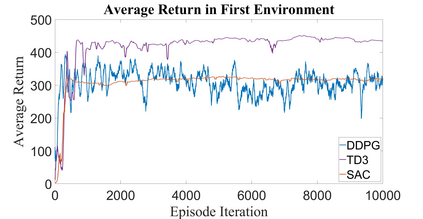
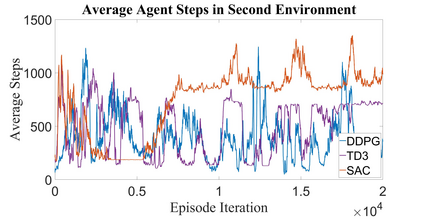
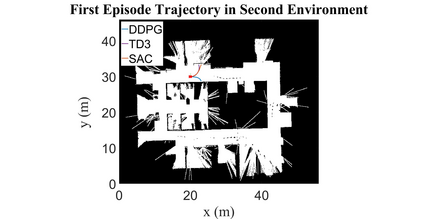
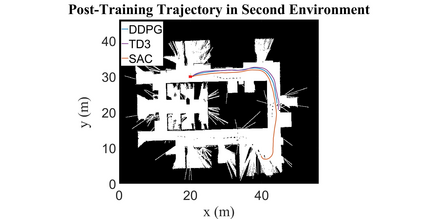
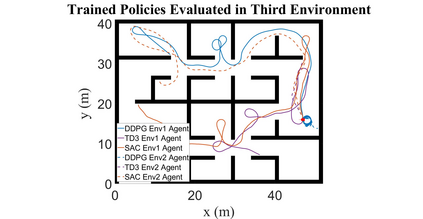
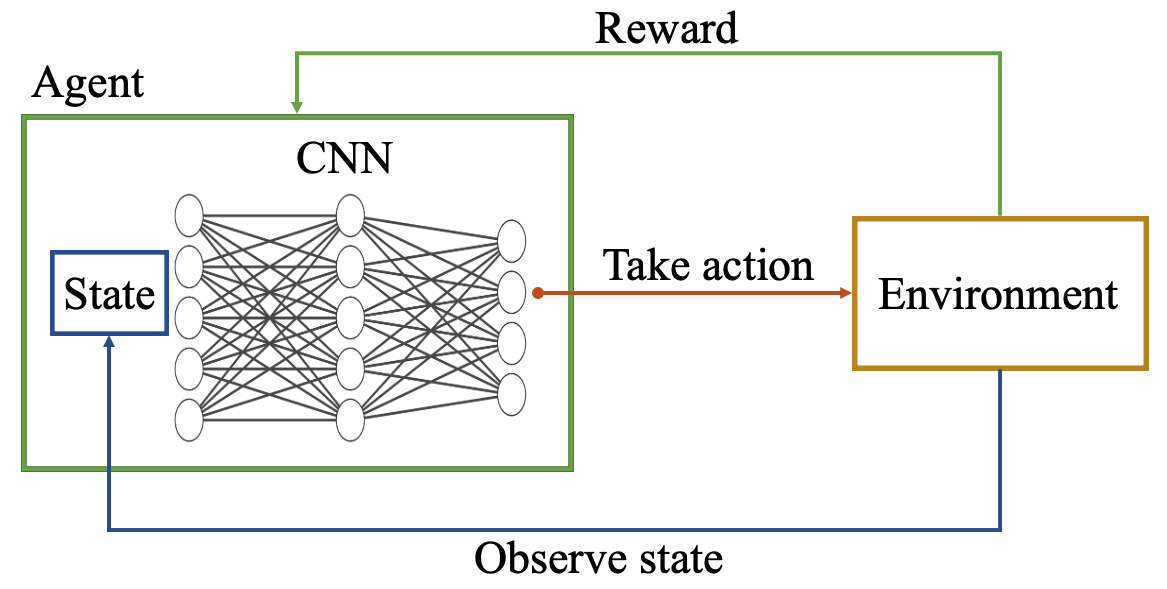
Autonomous Ground Vehicles (AGVs) are essential tools for a wide range of applications stemming from their ability to operate in hazardous environments with minimal human operator input. Efficient and effective motion planning is paramount for successful operation of AGVs. Conventional motion planning algorithms are dependent on prior knowledge of environment characteristics and offer limited utility in information poor, dynamically altering environments such as areas where emergency hazards like fire and earthquake occur, and unexplored subterranean environments such as tunnels and lava tubes on Mars. We propose a Deep Reinforcement Learning (DRL) framework for intelligent AGV exploration without a-priori maps utilizing Actor-Critic DRL algorithms to learn policies in continuous and high-dimensional action spaces, required for robotics applications. The DRL architecture comprises feedforward neural networks for the critic and actor representations in which the actor network strategizes linear and angular velocity control actions given current state inputs, that are evaluated by the critic network which learns and estimates Q-values to maximize an accumulated reward. Three off-policy DRL algorithms, DDPG, TD3 and SAC, are trained and compared in two environments of varying complexity, and further evaluated in a third with no prior training or knowledge of map characteristics. The agent is shown to learn optimal policies at the end of each training period to chart quick, efficient and collision-free exploration trajectories, and is extensible, capable of adapting to an unknown environment with no changes to network architecture or hyperparameters.
翻译:自主地面飞行器(AGV)由于其在人类操作者投入极少的情况下在危险环境中运作的能力而成为各种应用的基本工具。高效有效的运动规划对于AGV的成功运作至关重要。常规运动规划算法依赖于事先对环境特性的了解,在信息贫乏、动态变化的环境中,例如发生火灾和地震等紧急危险的地区,以及火星隧道和熔岩管等未探索的地下环境,具有有限的效用。我们提议了一个深度强化学习(DRL)框架,用于智能的AGV探索,而没有利用超常-Critic DRL算法在机器人应用所需的连续和高度行动空间学习政策,而没有利用优先地图进行探索。DRL算法、DDPG、TD3和SAC结构包括供评论者和行为者的反馈神经网络,在这种环境中,行为者网络对当前投入的线性和角形速度控制行动进行战略化,由评论性网络加以评估,以最大限度地获得累积的奖励。三种离政策之外的DRL算法、DDPG、TD3和SAC算法的算法,在一种不甚懂的、不甚懂的网络或深的地理环境上,在一种不熟悉的、不熟悉、不熟悉的、不熟悉的、不熟悉的、不熟悉的、不熟悉的地理结构中,在一种不熟悉的、不熟悉环境中,在一种不熟悉的学习的、不熟悉的学习环境上,在一种不熟悉的、不熟悉的、不熟悉的、不熟悉的地理结构中,在两种环境中,在一种不熟悉的、不熟悉的、不熟悉的、不熟悉的、不熟悉的地理环境里深的地理环境中,在一种不经过或深的、不经过的、不经过的、不经过的、不经过的、不经过的、不经过的、不经过的、不经过的、不经过的学习的、不经过的地理环境上,在一种环境上,在一种环境上,在一种环境上,在一种环境上,在一种环境上,在一种环境上,在一种环境上,在一种环境上,在一种环境上,在一种环境上,在一种不深的、不经过的、不及深的学习的、不深的、不深的学习的、不深的学习的、没有的、不经过的、不深的、不