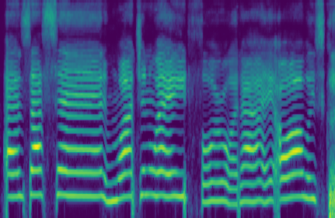
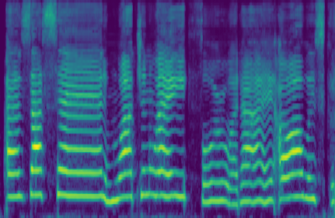
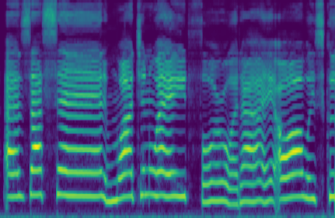
In this paper, we propose a differentiable WORLD synthesizer and demonstrate its use in end-to-end audio style transfer tasks such as (singing) voice conversion and the DDSP timbre transfer task. Accordingly, our baseline differentiable synthesizer has no model parameters, yet it yields adequate synthesis quality. We can extend the baseline synthesizer by appending lightweight black-box postnets which apply further processing to the baseline output in order to improve fidelity. An alternative differentiable approach considers extraction of the source excitation spectrum directly, which can improve naturalness albeit for a narrower class of style transfer applications. The acoustic feature parameterization used by our approaches has the added benefit that it naturally disentangles pitch and timbral information so that they can be modeled separately. Moreover, as there exists a robust means of estimating these acoustic features from monophonic audio sources, it allows for parameter loss terms to be added to an end-to-end objective function, which can help convergence and/or further stabilize (adversarial) training.
翻译:在本文中,我们提出一个不同的World合成器,并展示其在终端到终端音风格传输任务中的用途,如(播音)语音转换和DDSPtmbre传输任务。因此,我们的基线不同合成器没有模型参数,但能产生适当的合成质量。我们可以通过将轻量黑盒黑盒后网附加到基准输出中进一步处理以提高忠诚度,来扩展基准合成器。另一种不同的方法考虑直接提取源源的引用频谱,这可以改善自然性,尽管风格传输应用的种类比较狭窄。我们方法使用的声学特征参数参数还具有额外的好处,即它自然分解投投投投投投球和滴盘信息,从而可以分别制作模型。此外,由于存在着一种从单声音源估算这些声学特征的有力手段,因此可以将参数损失术语添加到终端至终端目标功能中,这将有助于趋同和/或进一步稳定(对抗性)训练。